
Aktualny adres repozytorium to: https://git.eadministracja.nask.pl/api/packages/ezdrp/helm
Uwaga! Przed aktualizacją należy wykonać backup środowiska.
Proces aktualizacji należy rozpocząć od zalogowania się do Ranchera za pomocą dowolnej przeglądarki. Zainstalowany Rancher dostępny będzie pod adresem: https://ip_serwera:8443. Po zaakceptowaniu certyfikatu wyświetli się strona powitalna Ranchera.
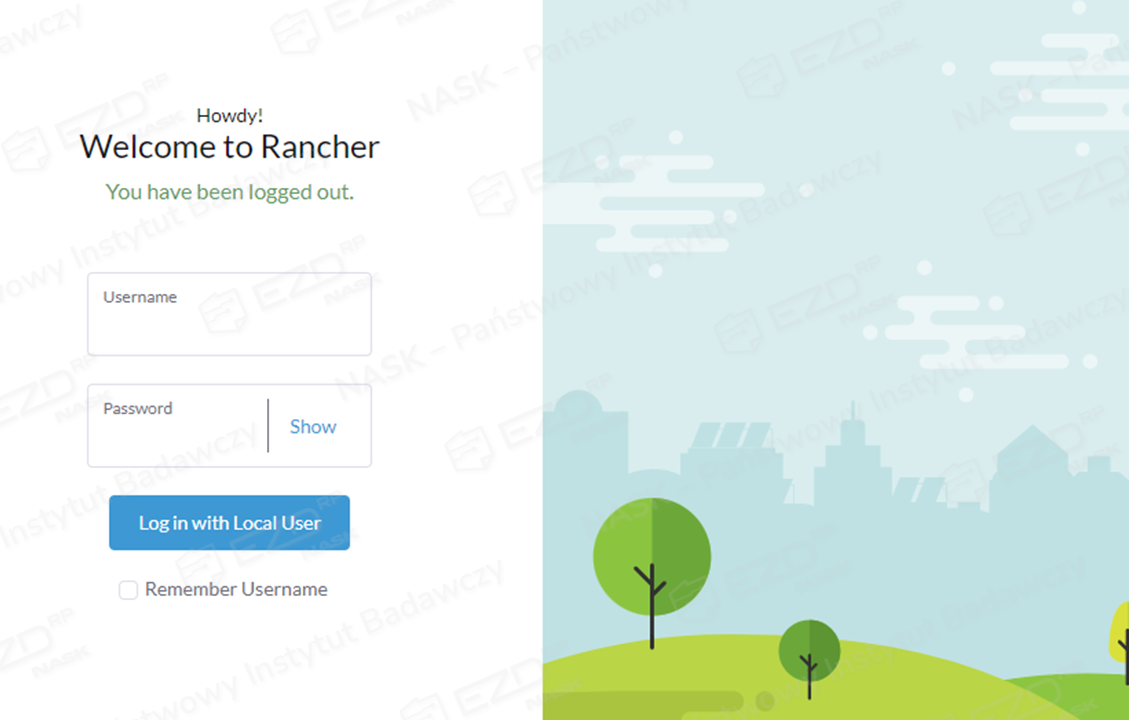
Domyślnym loginem użytkownika jest admin. W polu Password wpisujemy swoje, wcześniej ustalone hasło. Następny krok to wybranie odpowiedniego, utworzonego wcześniej klastra. W naszym przykładzie jest to klaster pilotaz.
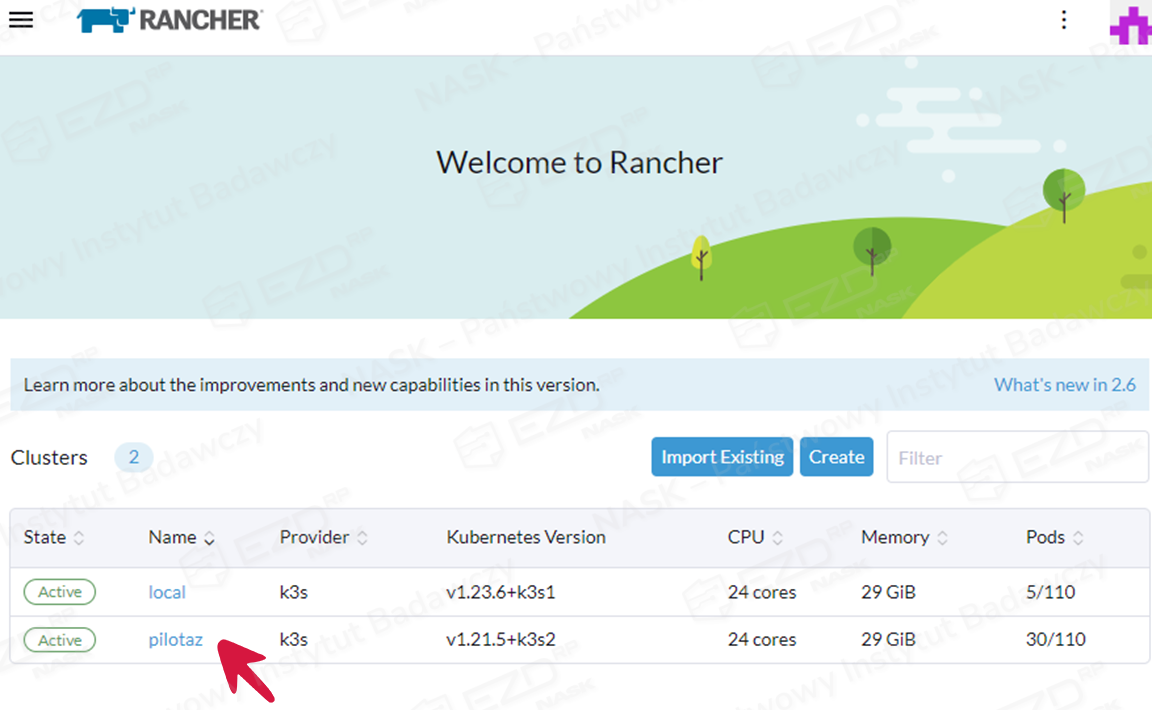
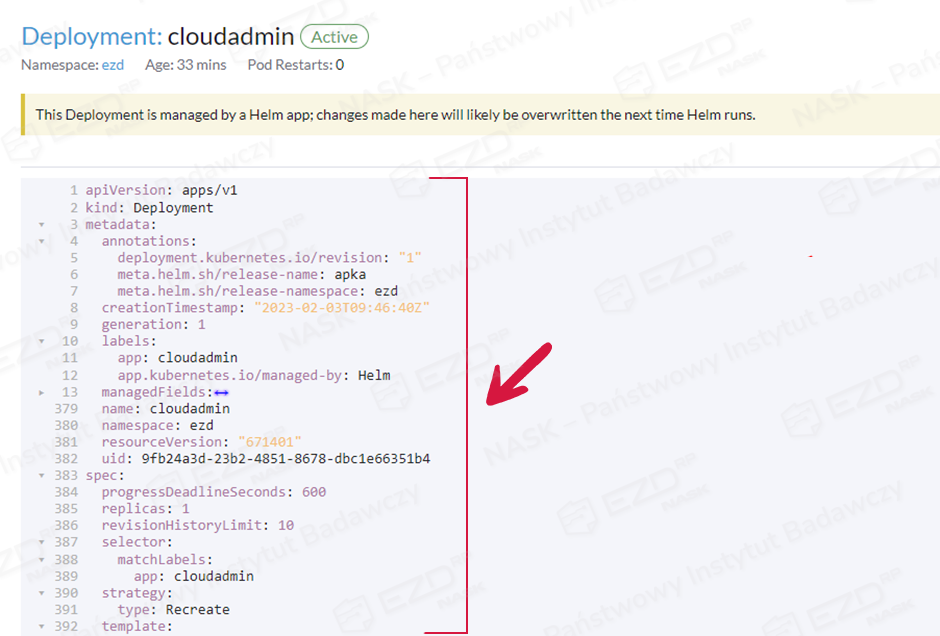
Po wykonaniu archiwizacji środowiska EZD RP (backupu), wykonujemy kopię Cloudadmin. W tym celu należy wybrać Workloads > Deployments.
Następnie wybieramy Cloudadmin, klikamy ikonę menu podręcznego (trzy kropki) i opcję Edit YAML.
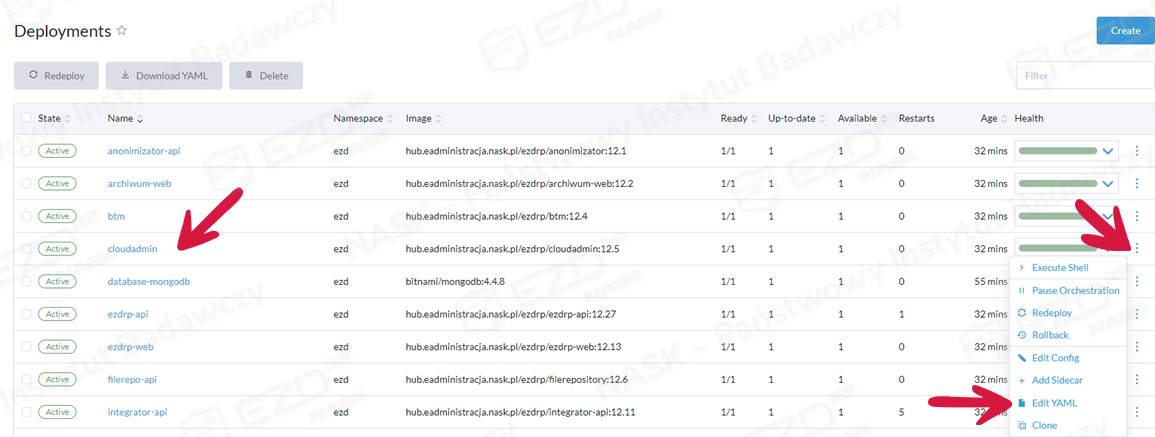
Należy skopiować całą zawartość YAML i zapisać ją w pliku tekstowym, np. przy użyciu edytora Notepad.
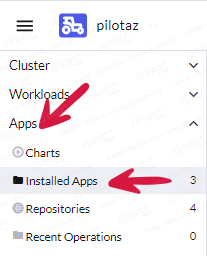
Przechodzimy do aktualizacji aplikacji. W tym celu klikamy Apps > Installed Apps.
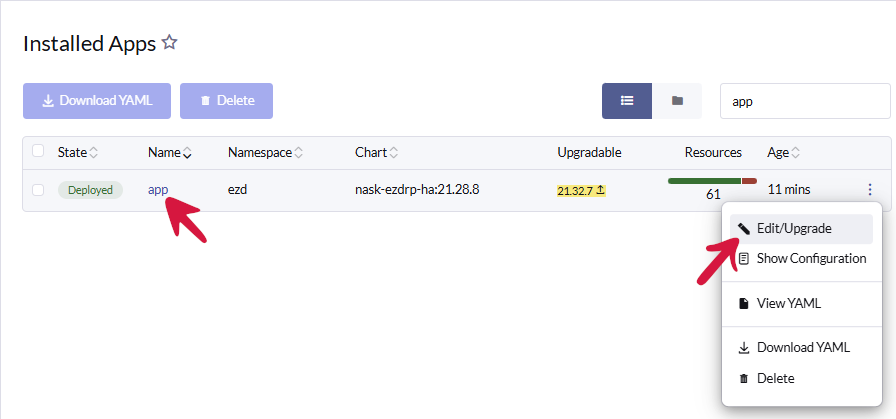
Zaznaczamy aplikację (w naszym przykładzie o nazwie app), klikamy ikonę menu podręcznego (trzy kropki) i wybieramy opcję Edit/Upgrade.
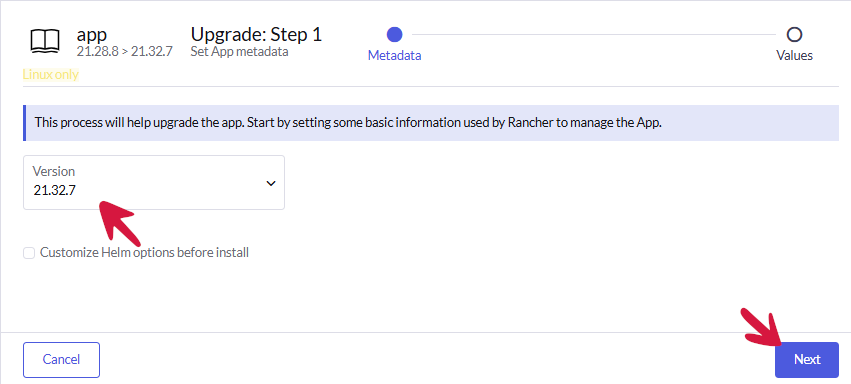
Odszukujemy wersję 21.32.x i klikamy Next.
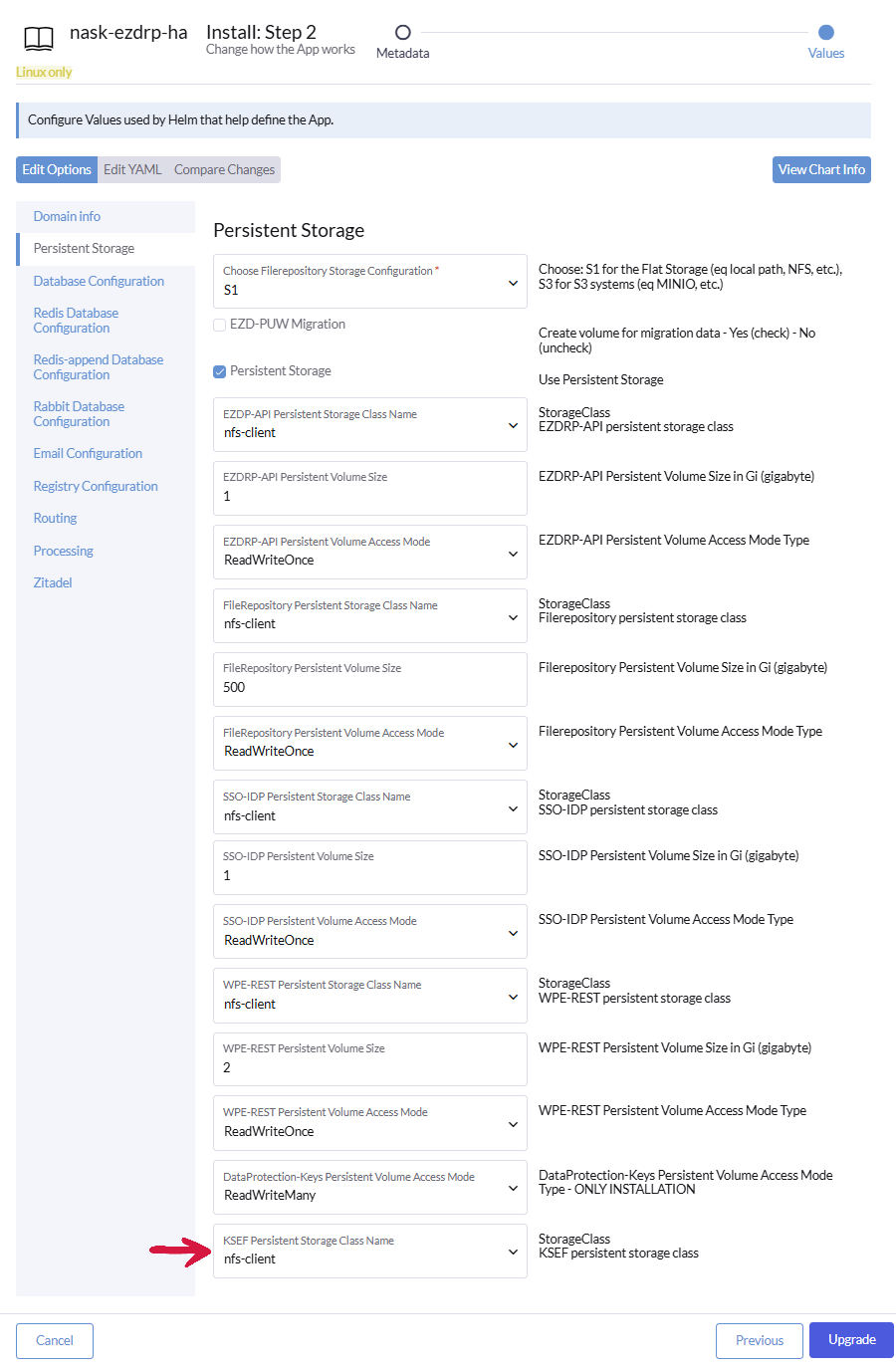
W zakładce Presistent Storage na samym dole pojawiła się nowa opcja KSEF Presistent Storage Class Name należy wybrać nfs-client.
Następnie należy kliknąć zakładkę Edit YAML i zmienić wartości flagi poniżej.
| Flaga | Wartość | Opis |
|---|---|---|
| Ezdrp_Feature_EpuapWysylkaPlikowStrumieniowo | Enabled | Zoptymalizowany sposób wysyłania plików przez ePUAP. |
Po wprowadzeniu zmian klikamy przycisk Upgrade.
Po prawidłowej aktualizacji w logu pojawi się napis SUCCESS.

Następnie należy dodać nowy rekord DNS o nazwie.
connectors
Najczęstsze problemy
Brak postępów aktualizacji ciągły komunikat PersistentVolumeClaim is not bound: ezd/ksef-client.

Nie został wybrany prawidłowy KSEF Presistent Storage Class Name w czasie aktualizacji.
W pierwszej kolejności w Rancher należy zeskalować deploymenty do 0 w Workloads -> Deployments o nazwach ksef-client oraz ksef-pdf-generator.

Następnie usuwamy nieutworzone PVC w Storage -> PersistentVolumeClaims o nazwie ksef-client.
Można użyć komend kubectl jak poniżej uzupełniając o swoją nazwę namespace.

kubectl scale deployment/ksef-client --replicas=0 -n ezd
kubectl scale deployment/ksef-pdf-generator --replicas=0 -n ezd
kubectl delete pvc ksef-client -n ezdPonownie wykonujemy aktualizację wybierając prawidłowe KSEF Presistent Storage Class Name w naszym przypadku nfs-client.
Po wprowadzeniu zmian klikamy przycisk Upgrade.
Brak postępów aktualizacji ciągły komunikat PersistentVolumeClaim is not bound data-protection-keys.
Problem z utworzeniem PVC data-protection-keys dla StorageClasses local-path (stare środowiska oparte w pełni na kubernetes) przy aktualizacji do wersji 21.22.7.
W pierwszej kolejności weryfikujemy w Rancher, pody ezdrp-api i signalr Workloads > Pods czy mają problem z uruchomieniem, w logu od aktualizacji pojawi się komunikat jak poniżej PersistentVolumeClaim is not bound data-protection-keys.
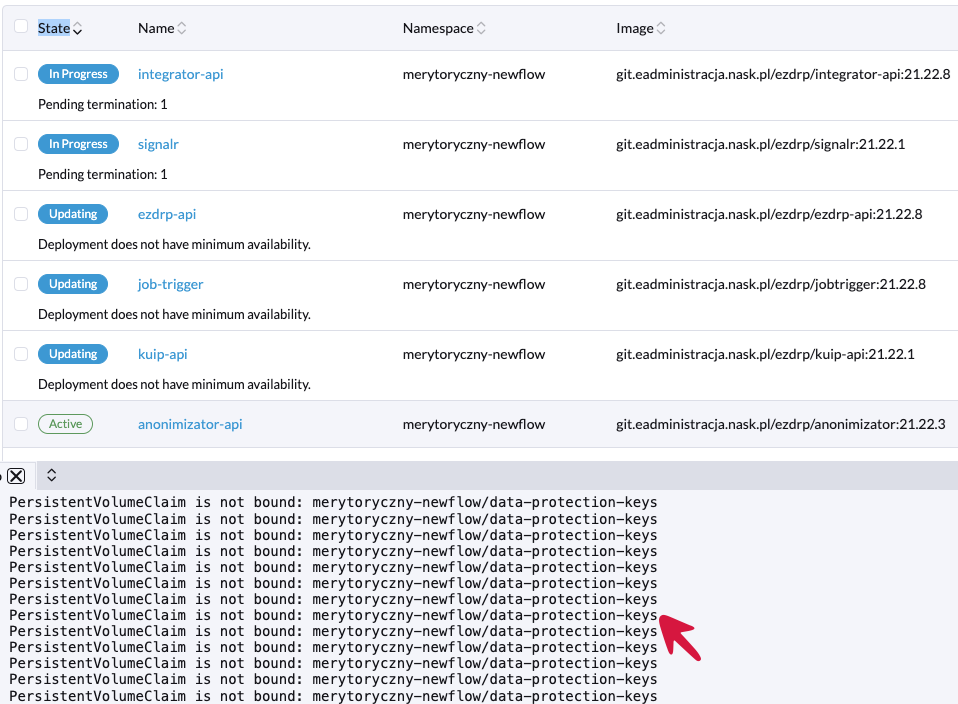
A w Storage > PersistentVolumeClaim przy PVC data-protection-keys wyświetli się Pending

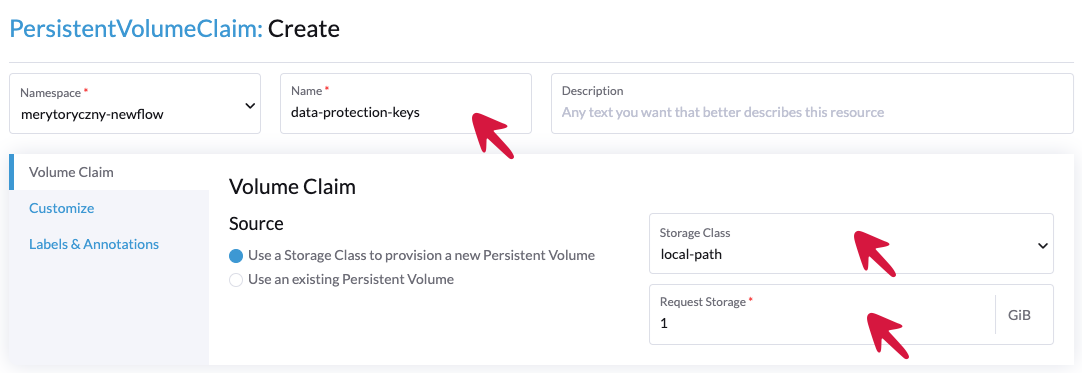
Zaznaczamy problematyczne PVC i je usuwamy, teraz naciskamy przycisk Create w name wprowadzamy nazwę data-protection-keys w polu Storage Class wybieramy opcje local-path a w Request Storage wpisujemy 1 i zatwierdzamy create.
Pojawienie się komunikatu w zakładce Workloads > Pods 0/3 nodes are available: 3 Insufficient cpu. preemption: 0/3 nodes are available: 3 No preemption victims found for incoming pod..

Należy przejść do zakładki Workloads > Deployments, odszukać pod o nazwie ezdrp-api kliknąć trzy kropki i wybrać Edit Config.
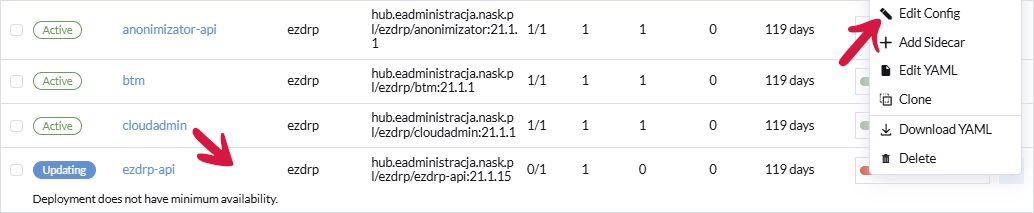
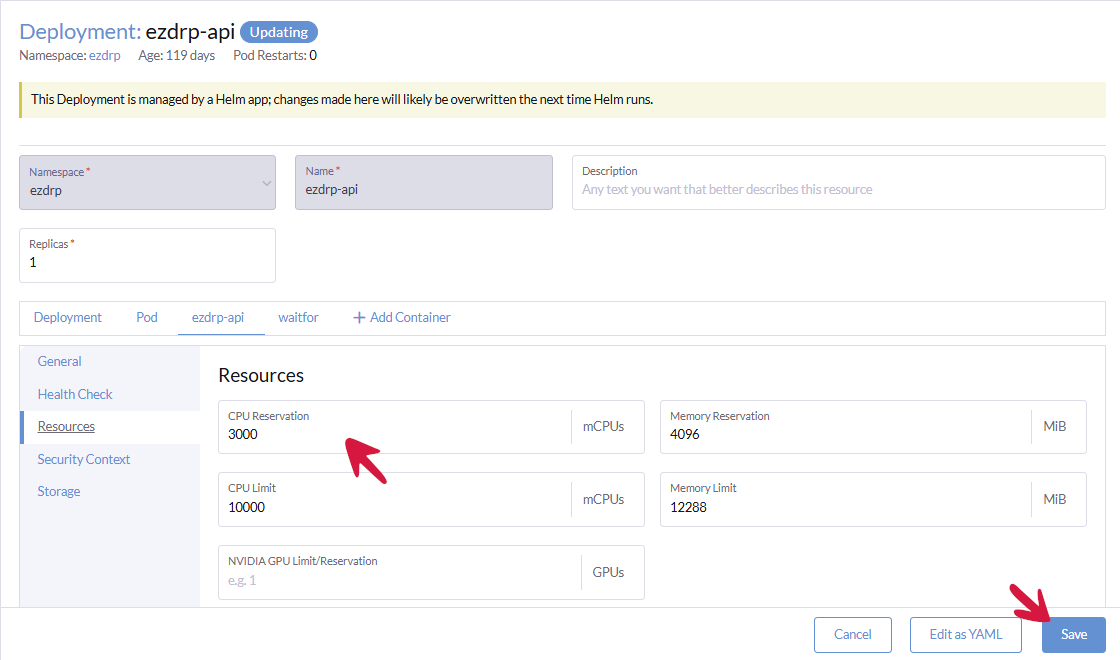
Przechodzimy do zakładki Resources i zmieniamy CPU Reservation z 3000 na 2000
Zatwierdzamy Save
Pojawienie się komunikatu volume-owner-hack przy uruchamianiu się podu filerepo-api z statusem Init:0/1.

W przypadku posiadania dość sporej ilości dokumentów w storage, uruchomienie tego poda może zająć więcej czasu.
Pojawienie się komunikatu volume-owner-hack przy uruchamianiu się podów ezdrp-api/sso-identityserver/filerepo-api/wpe-rest z statusem Init:crashloopback.

Aby rozwiązać ten problem, w pliku exports na serwerze NFS należy dodać parametr no_root_squash.
sudo nano /etc/exports
/nfs XXX.XXX.XXX.XXX(rw,sync,no_subtree_check,no_root_squash)Następnie należy zrestartować serwer NFS.
sudo systemctl restart nfs-serverW kolejnym kroku wykonujemy aktualizację. Jeśli pody uruchomią się prawidłowo, należy ponownie edytować plik exports i usunąć parametr no_root_squash.
sudo nano /etc/exports
/nfs XXX.XXX.XXX.XXX(rw,sync,no_subtree_check)Na koniec restartujemy serwer NFS.
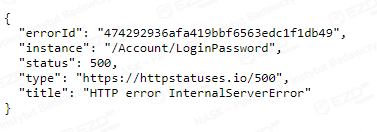
sudo systemctl restart nfs-serverPojawienie się komunikatu podczas próby logowania do systemu.
Przechodzimy do aktualizacji aplikacji. W tym celu klikamy Apps > Installed Apps.
Zaznaczamy aplikację (w naszym przykładzie o nazwie app), klikamy ikonę menu podręcznego (trzy kropki) i wybieramy opcję Edit/Upgrade.
Odszukujemy wersję 21.x i klikamy Next.
Należy kliknąć zakładkę Edit YAML.
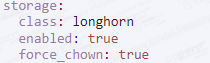
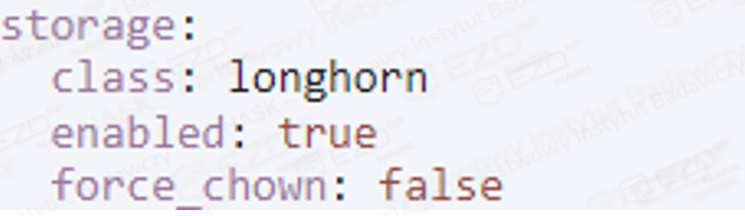
Odnajdujemy linijkę force_chown, zmieniając parametr na true.
Widok przed zmianą:
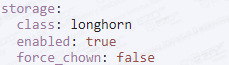
Widok po zmianie:
Klikamy przycisk Upgrade.
Po prawidłowej aktualizacji w logu pojawi się napis SUCCESS.

Ponownie wykonujemy zmianę w linijce force_chown, lecz tym razem zamieniamy parametr true na false.
Widok przed zmianą:
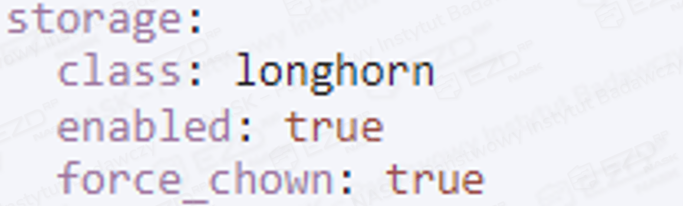
Widok po zmianie:
Klikamy przycisk Upgrade.
Po prawidłowej aktualizacji w logu pojawi się napis SUCCESS.