
Prezentujemy opis przykładowej instalacji złożonej z:
- 3 × Ubuntu 24.04 LTS (master 1, master 2, master 3…)
- 1 × Ubuntu 24.04 LTS (baza danych Postgres)
- 1 × Ubuntu 24.04 LTS (Rabbit, Redis)
- 2 × Ubuntu 24.04 LTS (HA Proxy load balancer 1, HA Proxy load balancer 2)
- 1 × Ubuntu 24.04 LTS (storage NFS)
- 1 × Ubuntu 24.04 LTS (Rancher)
- 1 × VIP (Virtual IP)
Wymagania serwerowe
Przed przystąpieniem do instalacji NFS, zewnętrznych baz danych Postgres, Redis i Rabbit, load balancera (HAProxy) oraz aplikacji EZD RP, należy przygotować maszyny wirtualne lub serwery fizyczne o parametrach zależnie od ilości obsługiwanych użytkowników per instancja:
| Liczba użytkowników | Mastery (vCPU/ GB RAM) | Baza danych (vCPU/ GB RAM) | Redis/RabbitMQ (vCPU/ GB RAM) | HAProxy (vCPU/ GB RAM) | NFS (vCPU/ GB RAM) | Rancher (vCPU/ GB RAM) |
|---|---|---|---|---|---|---|
| 1000 | 3 × (6 vCPU/ 16 GB) | 6 vCPU/ 8 GB | 2 vCPU/ 6 GB | 2 × (4 vCPU/ 4 GB) | 4 vCPU/ 4 GB | 4 vCPU/ 16 GB |
| 2000 | 3 × (8 vCPU/ 22 GB) | 8 vCPU/ 16 GB | 2 vCPU/ 6 GB | 2 × (4 vCPU/ 4 GB) | 4 vCPU/ 4 GB | 4 vCPU/ 16 GB |
| 5000 | 3 × (16 vCPU/ 24 GB) | 16 vCPU/ 24 GB | 4 vCPU/ 8 GB | 2 × (8 vCPU/ 4 GB) | 4 vCPU/ 4 GB | 4 vCPU/ 16 GB |
| 10 000 | 3 × (20 vCPU/ 32 GB) | 32 vCPU/ 64 GB | 4 vCPU/ 8 GB | 2 × (8 vCPU/ 4 GB) | 4 vCPU/ 4 GB | 4 vCPU/ 16 GB |
Wersje wspieranych baz danych/brokerów
- Postgresql 18.*
- Redis 7.*
- Rabbit 4.*
Pamięć masowa (HDD): rekomendowane co najmniej 100 GB przestrzeni na szybkich dyskach NVMe/SSD na potrzeby obliczeń i bufora danych, w przypadku serwera NFS conajmniej 3 TB. Należy pamiętać, że docelowa przestrzeń dyskowa jest zależna od liczby oraz typu, wielkości przetwarzanych dokumentów w jednostce.
Inne: certyfikat Wildcard dla witryny, klucz prywatny i publiczny w formacie Unix, dane konta e-mailowego przeznaczonego do powiadomień systemowych (host_ip, username, password, port), Ubuntu w wersji 24.04 LTS. RKE2 domyślnie korzysta z adresacji 10.42.0.0/16 i 10.43.0.0/16
Krok 1. Instalacja serwera NFS
1.1 Aktualizacja systemu i instalacja narzędzi
Aby rozpocząć instalację serwera NFS, najpierw należy zaktualizować system oraz zainstalować niezbędne narzędzia, co zapewni stabilność i aktualność oprogramowania.
sudo apt update && sudo apt upgrade
1.2 Instalacja NFS
Po zaktualizowaniu systemu, kolejnym krokiem jest instalacja serwera NFS, który umożliwi udostępnianie zasobów plikowych w sieci.
sudo apt install nfs-server

1.3 Konfiguracja pliku exports i przygotowanie folderu NFS
W celu udostępnienia folderów w sieci, konieczna jest konfiguracja pliku exports oraz przygotowanie odpowiedniego katalogu NFS, który będzie dostępny dla innych użytkowników.
sudo nano /etc/exports
Dodajemy wpis jak poniżej, gdzie XXX.XXX.XXX.XXX to adresy IP serwerów master.
/nfs XXX.XXX.XXX.XXX(rw,sync,no_subtree_check,no_root_squash) 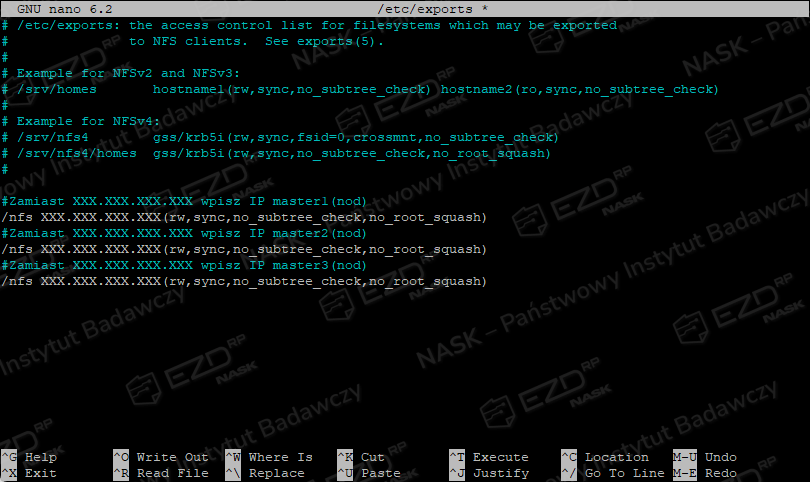
Należy utworzyć folder NFS.
sudo mkdir /nfsNastępnie nadajemy uprawnienia.
sudo chown -R nobody:nogroup /nfsTen etap kończymy restartem serwera NFS.
sudo systemctl restart nfs-serverKrok 2. Instalacja baz danych
Przed przystąpieniem do instalacji zewnętrznych baz danych (PostgreSQL, Redis) i oprogramowania pośredniczącego (RabbitMQ) należy przygotować maszynę wirtualną lub sprzęt fizyczny (serwer) spełniające określone wymagania.
2.1 Przygotowanie Ubuntu pod instalacje baz danych z Ansible
Po wcześniejszym przygotowaniu serwera Ubuntu oraz utworzeniu konta z uprawnieniami administratora (sudo), z którego przeprowadzimy instalację systemu.
Wiele dystrybucji Linuksa zawiera domyślnie zainstalowany Git. Aby to sprawdzić, należy otworzyć Terminal w systemie Ubuntu (wszystkie poniższe polecenia wykonujemy w Terminalu) i uruchomić polecenie, które wyświetla aktualność pakietów.
sudo apt update && sudo apt upgradePojawi się prośba o podanie utworzonego podczas instalacji Ubuntu hasła użytkownika z uprawnieniami root. Należy je wpisać i nacisnąć Enter. Poniżej widoczny jest przykład zaktualizowanych pakietów.
Następnie wykonujemy polecenie sprawdzające, czy w systemie jest zainstalowany Git.
git versionJeżeli w odpowiedzi uzyskamy komunikat podobny do pokazanego poniżej, można pominąć kolejny punkt (2.2 Instalacja Git).

2.2 Instalacja Git
Aby pobrać paczkę instalacyjną baz danych dla EZD RP, trzeba najpierw sklonować repozytorium przy użyciu Git. Jeżeli Git nie był zainstalowany w naszej dystrybucji domyślnie, należy go zainstalować za pomocą Terminala (wykonujemy w nim wszystkie poniższe polecenia).
sudo apt install gitW celu weryfikacji poprawności instalacji należy wykonać kolejne polecenie.
git versionW odpowiedzi powinniśmy uzyskać komunikat podobny do pokazanego poniżej.
2.3 Instalacja Ansible 2.20
W pierwszej kolejności trzeba sklonować repozytorium.
git clone --branch=stable-2.20 https://github.com/ansible/ansible.gitRozpocznie się proces klonowania, po którym wyświetli się szczegółowa informacja o wykonaniu zadania.

Następnie należy zainstalować sshpass.
sudo apt install sshpassPo wykonaniu polecenia rozpocznie się proces instalacji.
Instalujemy Python PIP (menedżer pakietów).
sudo apt install python3-pipPojawi się pytanie z opcją zatwierdzenia procesu instalacji. Wybieramy Y i naciskamy Enter.
Po rozpoczęciu instalacji wyświetli się komunikat.

W następnej kolejności wykonujemy symlink (dowiązanie symboliczne) dla Pythona 3.
sudo ln -s /usr/bin/python3 /usr/bin/pythonPrzechodzimy do sklonowanego katalogu.
cd ansibleInstalujemy środowisko Ansible.
source ./hacking/env-setupPo poprawnym wykonaniu polecenia pojawi się stosowny komunikat.
Następnie doinstalowujemy moduły Pythona niezbędne do poprawnego działania Ansible.
python -m pip install --user -r ./requirements.txt --break-system-packagesRozpocznie się proces pobierania i instalacji modułów Pythona. Po poprawnej instalacji pojawi się komunikat.
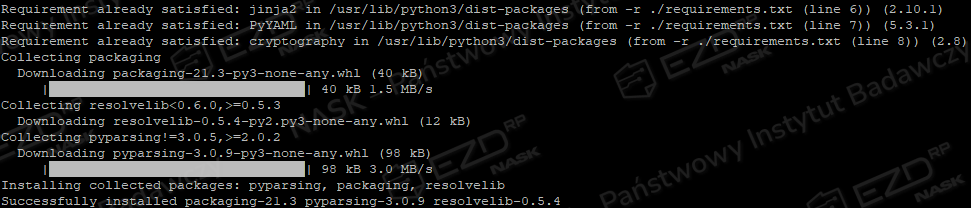
Kolejna czynność to weryfikacja instalacji.
ansible --versionRezultatem wykonania powyższego polecenia powinien być wynik podobny do widocznego na zrzucie.

2.4 Pobieranie paczki instalacyjnej baz danych dla EZD RP
Najpierw przechodzimy do katalogu domowego.
cd $HOMEPobieramy paczkę instalacyjną za pomocą poniższego polecenia.
wget https://podrecznik.ezdrp.gov.pl/site/uploads/ezd-database-install.tar --no-check-certificatePo pobraniu paczki pojawi się komunikat, że została ona zapisana.

Następnie należy rozpakować paczkę i przejść do katalogu ezd-database-install.
tar -xvf ezd-database-install.tarPo wykonaniu powyższej komendy paczka zostanie rozpakowana.
Przechodzimy do rozpakowanego katalogu.
cd ezd-database-install/Na tym etapie mamy gotowe następujące elementy:
- serwer Ubuntu
- serwer Ubuntu z Git oraz Ansible
- rozpakowaną paczkę instalacyjną baz danych dla EZD RP
2.5 Instalacja Ansible Collections
Zanim przystąpimy do konfiguracji playbooków, musimy wykonać instalację kolekcji. W tym celu należy przejść do utworzonego wcześniej katalogu domowego za pomocą komendy cd $HOME/ezd-database-install.
Następnie należy wykonać w Terminalu wszystkie poniższe polecenia (osobno).
ansible-galaxy collection install community.general
ansible-galaxy collection install community.postgresql
ansible-galaxy collection install community.rabbitmq
Po pomyślnie przeprowadzonej instalacji wyświetlone zostaną stosowne komunikaty „successfully”.
2.6 Przygotowanie hosta
Kolejną czynnością, jaką należy wykonać, jest przygotowanie pliku, dzięki któremu będzie możliwa komunikacja Ubuntu z serwerem bazodanowym. Plik do edycji znajduje się w lokalizacji:
nano inventory/hosts.yamlPrzykładowa budowa pliku inventory widoczna jest poniżej.
all:
vars:
ansible_user: twoj_uzytkownik
ansible_ssh_pass: twoje_haslo
ansible_sudo_pass: twoje_haslo
host_key_checking: false
db:
hosts:
db-1:
ansible_host: XXX.XXX.XXX.XXX
redisrabbit:
hosts:
db-2:
ansible_host: XXX.XXX.XXX.XXX
Wprowadzamy utworzonego wcześniej użytkownika z uprawnieniami sudo i jego hasło, a w linijce ansible_host db podajemy adres IP serwera bazodanowego postgres. Natomiast w linijce ansible_host redisrabbit wprowadzamy analogiczne dane dla serwera, na którym będą instalowane silniki Redis i RabbitMQ.
2.7 Weryfikacja poprawności konfiguracji
Na tym etapie sprawdzamy, czy możliwa jest komunikacja z serwerem bazdanowym. Wykonujemy w Terminalu poniższe polecenie.
ansible all -m pingO poprawnym wykonaniu polecenia informuje komunikat.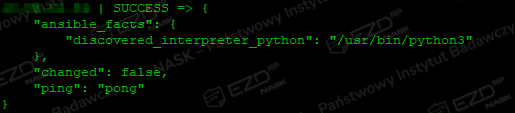
2.8 Modyfikacja plików konfiguracyjnych bazy danych (opcjonalnie)
Aby dokonać zmian domyślnych nazw użytkowników i baz danych można je zmodyfikować w pliku poniżej.
nano group_vars/all.yaml2.9 Instalacja bazy danych pod MS SQL, zamiast postgresql (opcjonalnie)
W przypadku gdy wybrany został silnik MS SQL, to należy wykonać dodatkowo punkt 1 i 2 z instrukcji.
2.10 Instalacja usług
W ostatnim kroku wykonujemy instalację i konfigurację baz danych (PostgreSQL, Redis oraz RabbitMQ)
ansible-playbook main_playbook.yamlPo wykonaniu komendy podajemy w Terminalu hasło do Ubuntu.
Efektem końcowym instalacji będzie podsumowanie z danymi dostępowymi do baz danych. Trzeba je skopiować i przechowywać w bezpiecznym miejscu.

Szczególną uwagę należy zwrócić na licznik przy pozycji failed. Jeśli pojawią się jakieś błędy, musimy sprawdzić powyższego loga i zweryfikować konfigurację.
Zalecenia
rm inventory/hosts.yamlKrok 3. Instalacja i konfiguracja HAProxy
3.1 Aktualizacja systemu
Zanim rozpoczniemy instalację HAProxy, upewnijmy się, że nasz system operacyjny jest zaktualizowany. Aby to zrobić, uruchamiamy następujące polecenie:
sudo apt update && sudo apt upgrade
3.2 Weryfikacja statusu firewalla
Przed przystąpieniem do instalacji warto sprawdzić, czy firewall jest wyłączony lub odpowiednio skonfigurowany, aby nie blokował portów wykorzystywanych przez HAProxy. Można to zrobić za pomocą polecenia:
sudo ufw status3.3 Instalacja HAProxy i Keepalived
Po upewnieniu się, że system jest zaktualizowany i gotowy, możemy przystąpić do instalacji HAProxy oraz Keepalived. Oba te narzędzia można zainstalować jednocześnie za pomocą następującego polecenia:
sudo apt install haproxy keepalived3.4 Konfiguracja HAProxy
Edytujemy plik haproxy.cfg.
sudo nano /etc/haproxy/haproxy.cfgWklejamy poniższą zawartość i dostosowujemy adresy IP do naszej infrastruktury. Poniższy przykład dotyczy środowiska z trzema serwerami master.
frontend http-frontend
bind :80
mode tcp
default_backend http-backend
backend http-backend
balance roundrobin
mode tcp
# w backend dodajemy wpisy odnośnie masterów
server web-master1 10.10.10.1:80 check
server web-master2 10.10.10.2:80 check
server web-master3 10.10.10.3:80 check
frontend https-frontend
bind :443
mode tcp
default_backend https-backend
backend https-backend
balance roundrobin
mode tcp
# w backend dodajemy wpisy odnośnie masterów
server web-master1 10.10.10.1:443 check
server web-master2 10.10.10.2:443 check
server web-master3 10.10.10.3:443 check
frontend kube-api
bind :9345
mode tcp
default_backend kube-api-backend
backend kube-api-backend
balance roundrobin
mode tcp
# w backend dodajemy tylko wpisy odnośnie masterów
server web-master1 10.10.10.1:9345 check
server web-master2 10.10.10.2:9345 check
server web-master3 10.10.10.3:9345 check
frontend stats
bind *:8404
mode http
stats enable
stats uri /stats
stats refresh 10s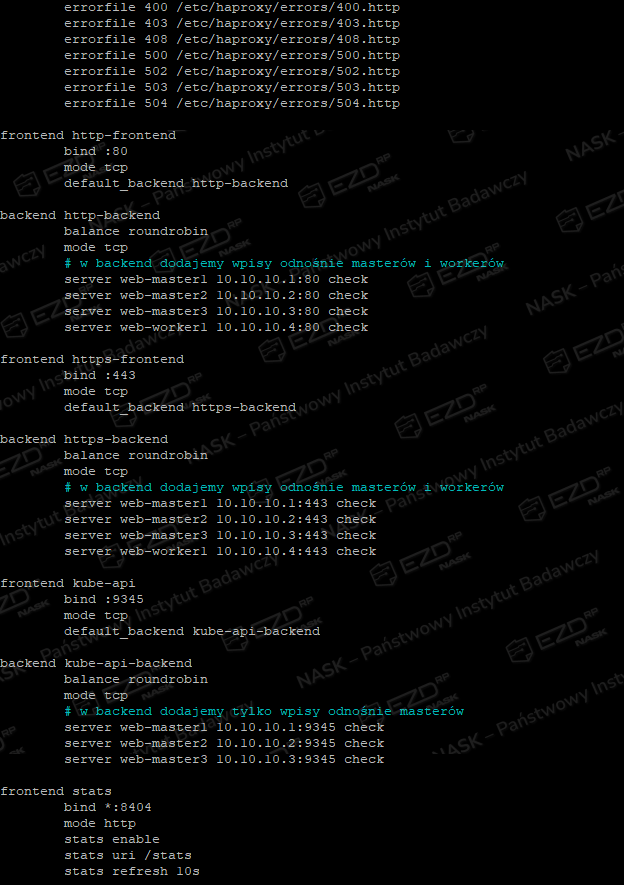
3.5 Autostart HAProxy
Aby zapewnić, że HAProxy będzie automatycznie uruchamiane po każdym restarcie systemu, musimy włączyć usługę HAProxy w trybie autostartu.
sudo systemctl enable haproxy3.6 Restart HAProxy
Po wprowadzeniu zmian w konfiguracji lub po instalacji warto zrestartować usługę HAProxy.
sudo systemctl restart haproxyW celu sprawdzenia poprawności load balancera, należy uruchomić w przeglądarce adres IP balancera z portem 8404 oraz dodać /stats przykładowo http://10.10.10.100:8404/stats
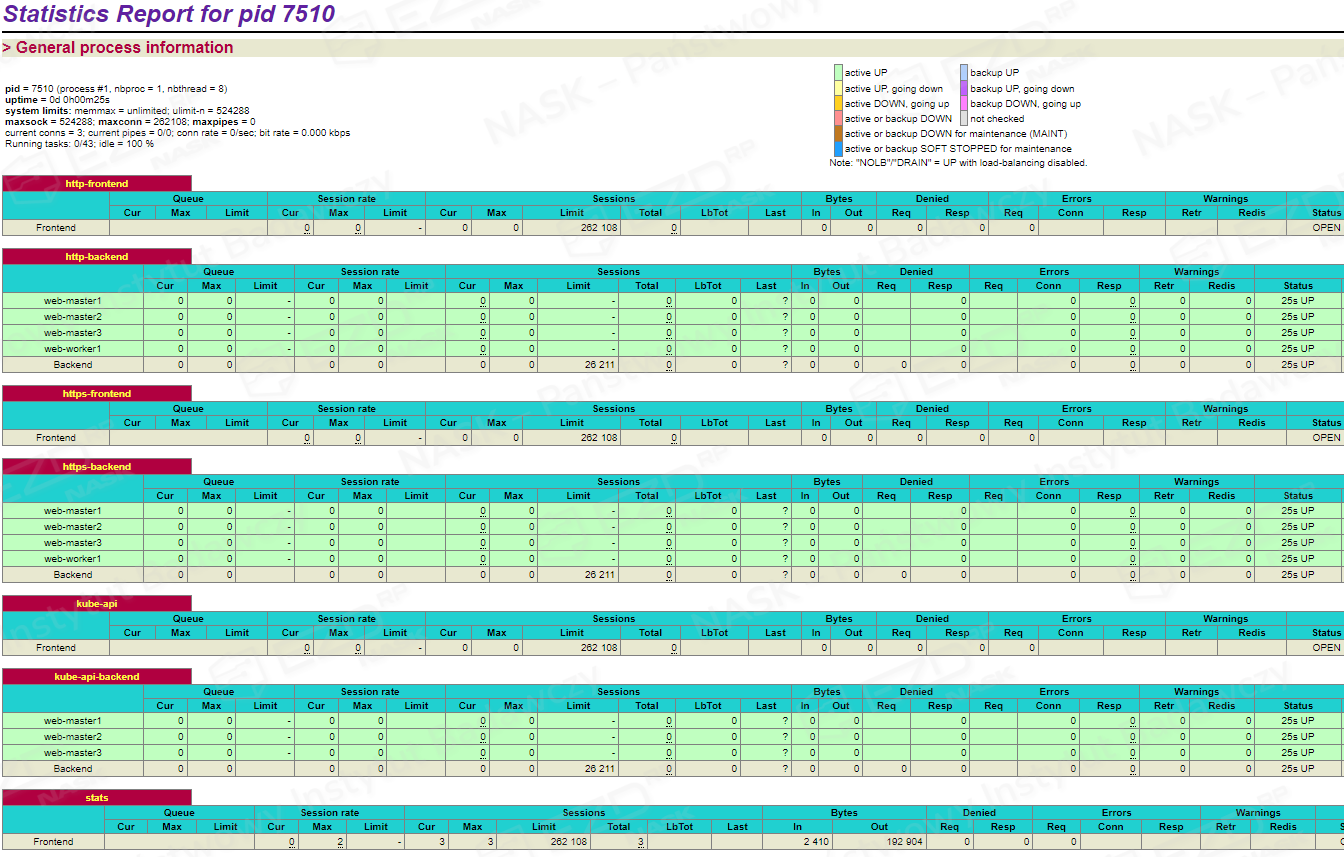
Jeśli w kolumnie Status widnieje wartość UP, oznacza to, że usługi działają prawidłowo. W przeciwnym razie należy zweryfikować poprawność konfiguracji danego serwera master.
3.7 Konfiguracja wysokodostępowego load balancera HAProxy oraz Keepalived
W celu zapewnienia wysokiej dostępności (HA) dla HAProxy, należy skonfigurować dwa serwery z zainstalowanym HAProxy oraz Keepalived. W razie awarii jednego z nich, Keepalived automatycznie przełączy ruch na działający serwer, co minimalizuje ryzyko przestojów.
3.7.1 Konfiguracja HAProxy na kolejnym serwerze według punktu 1 (load balancer 2)
Można przekopiować zawartość pliku haproxy.cfg z lokalizacji /etc/haproxy/ z jednego serwera na drugi.
3.7.2 Modyfikacja sysctl.conf (load balancer 1 i 2)
W następnym kroku edytujemy plik sysctl.conf.
sudo nano /etc/sysctl.confNa samym dole pliku dodajemy poniższą linię.
net.ipv4.ip_nonlocal_bind=1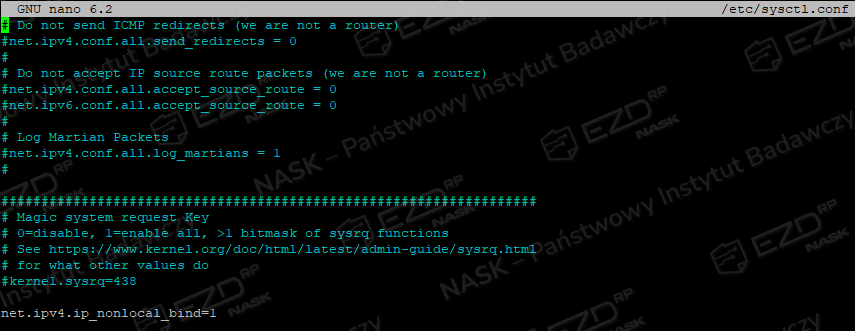 Zapisujemy plik i urchamiamy komendę.
Zapisujemy plik i urchamiamy komendę.
sudo sysctl -p3.7.3 Konfiguracja Keepalived (load balancer 1)
Tworzymy plik konfiguracyjny keepalived.conf na load balancer 1.
sudo nano /etc/keepalived/keepalived.confWklejamy poniższą treść, edytujemy linijkę z interfejsem oraz wirtualnym adresem IP (który nie jest przypisany do żadnego interfejsu sieciowego).
Nazwę interfejsu sieciowego można sprawdzić za pomocą następującego polecenia:
ip a | grep "state UP"vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VI_1 {
interface ens160 #wprowadzamy nazwę interfejsu zgodnie z naszą kartą sieciową
state MASTER
virtual_router_id 51
priority 101
virtual_ipaddress {
10.10.10.99 #wprowadzamy wirtualny adres IP(VIP)
}
track_script {
chk_haproxy
}
}3.7.4 Uruchomienie Keepalived na load balancer 1
Usługa Keepalived będzie odpowiedzialna za monitorowanie dostępności wirtualnego adresu IP i przełączanie go między serwerami w razie potrzeby. Aby ją włączyć, należy użyć poniższego polecenia.
sudo systemctl start keepalived3.7.5 Konfiguracja Keepalived na load balancer 2
Za pomocą poniższego polecenia tworzymy plik konfiguracyjny keepalived.conf na load balancer 2.
sudo nano /etc/keepalived/keepalived.confW tym pliku wklejamy konfigurację, upewniając się, że zmieniamy linijkę z nazwą interfejsu sieciowego oraz wirtualnym adresem IP. Ważne jest, aby wirtualny adres IP był taki sam, jak ustawiony na load balancer 1.
Aby sprawdzić nazwę interfejsu, którego będziemy używać, można użyć poniższego polecenia.
ip a | grep "state UP"vrrp_script chk_haproxy {
script "killall -0 haproxy"
interval 2
weight 2
}
vrrp_instance VI_1 {
interface ens160 #wprowadzamy nazwę interfejsu zgodnie z naszą kartą sieciową
state BACKUP
virtual_router_id 51
priority 100
virtual_ipaddress {
10.10.10.99 #wprowadzamy wirtualny adres IP(VIP)
}
track_script {
chk_haproxy
}
}3.7.6 Uruchomienie Keepalived na load balancer 2
Aby uruchomić usługę Keepalived, należy użyć poniższego polecenia.
sudo systemctl start keepalivedKrok 4. Konfiguracje na serwerze aplikacyjnym (pierwszy nod master 1)
4.1 Aktualizacja systemu oraz instalacja narzędzi
Zanim rozpoczniemy instalację narzędzi, należy upewnić się, że system jest w pełni zaktualizowany. W tym celu uruchamiamy poniższe polecenie:
sudo apt update && sudo apt upgradePo zakończeniu aktualizacji systemu, należy zainstalować narzędzia, które będą niezbędne do zarządzania klastrem Kubernetes oraz aplikacjami.
sudo snap install kubectl --classic
sudo snap install helm --classic
sudo apt install nfs-client


4.2 Weryfikacja statusu firewalla
Sprawdzamy status firewalla za pomocą jednej z dwóch poniższych komend.
sudo ufw statussudo iptables -v -LWynikiem powinien być komunikat o wyłączonym firewallu.

4.3 Wyłączenie partycji SWAP
Partycja wymiany (SWAP) to systemowa partycja występująca w systemach typu Unix. Służy do tymczasowego przechowywania danych w sytuacji, gdy ich ilość przekracza zasoby wolnej pamięci RAM lub gdy z różnych powodów korzystniej jest przechowywać je (lub ich część) na dysku twardym.
Pierwszą czynnością jest wyłączenie partycji SWAP.
sudo swapoff -aUsuwamy obraz pliku swap i robimy wykomentowanie w pliku fstab, aby nie uruchomił się przy starcie systemu operacyjnego.
sudo rm -f /swap.img
sudo sed -i 's/\/swap.img/#\/swap.img/g' /etc/fstab
Weryfikujemy wykomentowanie za pomocą polecenia poniżej.
sudo cat /etc/fstabRezultatem powinien być wynik podobny do tego poniżej.

4.4 Edycja hosts
Otwieramy plik hosts za pomocą poniższego polecenia.
sudo nano /etc/hostsNależy wkleić poniższe linijki na końcu pliku hosts, zmieniając XXX.XXX.XXX.XXX na odpowiednie adresy IP oraz nazwy hostów. To samo dotyczy wpisów dla load balancera. Nie należy wpisywać hosta, na którym wykonywana jest konfiguracja.
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master1
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master2
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master3
#loadbalancer
XXX.XXX.XXX.XXX nazwa_domenowa_vip4.5 Instalacja RKE2
W tym kroku zainstalujemy RKE2 (Rancher Kubernetes Engine 2), czyli lekką dystrybucję Kubernetesa stworzoną z myślą o prostszej i bezpieczniejszej implementacji klastra Kubernetes.
sudo curl -sfL https://get.rke2.io | sudo INSTALL_RKE2_VERSION=v1.34.1+rke2r1 sh -
4.6 Uruchomienie RKE2
W kolejnym kroku należy uruchomić i skonfigurować usługę RKE2, aby rozpocząć zarządzanie klastrem.
sudo mkdir -p /etc/rancher/rke2/
sudo nano /etc/rancher/rke2/config.yaml#server: https://nazwa_loadbalancera_vip:9345
#token: Tu wkleisz swój token po uruchomieniu klastra.
tls-san:
#Podaj nazwę loadbalancera VIP
- "nazwa_loadbalancera_vip"
#zamiast XXX.XXX.XXX.XXX wpisz adresy masterów klastra
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "127.0.0.1"
- "localhost"
#zamiast XXX.XXX.XXX.XXX wpisz adres aktualnego mastera
bind-address:
- "XXX.XXX.XXX.XXX"
advertise-address:
- "XXX.XXX.XXX.XXX"
node-ip:
- "XXX.XXX.XXX.XXX"
#selinux:
# - "true"Następnie uruchamiamy RKE2 na nodzie.
sudo systemctl enable --now rke2-server.serviceW razie problemów z uruchomieniem klastra RKE2, należy wykonać poniższą komendę, aby sprawdzić logi.
journalctl -u rke2-server.service -fWyciągamy token i podmieniamy go w pliku konfiguracyjnym.
sudo cat /var/lib/rancher/rke2/server/node-tokenNastępnie należy skopiować token i wkleić go od pliku konfiguracyjnego, usuwając znak hash (#) przed słowem token.
sudo nano /etc/rancher/rke2/config.yamlPo wprowadzeniu zmian konieczny jest restart usługi RKE2.
sudo systemctl restart rke2-server.service4.7 Dodanie uprawnień dla kubectl
Aby skonfigurować dostęp dla kubectl, należy wykonać poniższe polecenia:
mkdir .kube
sudo cp /etc/rancher/rke2/rke2.yaml .kube/config
sudo chmod 600 .kube/config
sudo chown $USER .kube/configNastępnie ustawiamy zmienną środowiskową KUBECONFIG, aby kubectl korzystał z odpowiedniego pliku.
export KUBECONFIG=.kube/configZa pomocą poniższego polecenia sprawdzamy, czy kubectl działa.
kubectl get nodes
Krok 5. Konfiguracja kolejnych nodów (master 2, master 3 itd.)
W tym kroku konfigurujemy kolejne nody klastra, aby mogły one dołączyć do istniejącej struktury.
5.1 Aktualizacja systemu oraz instalacja narzędzi
Na każdym z dodatkowych nodów wykonujemy poniższe polecenia, aby zaktualizować system i zainstalować niezbędne narzędzia.
sudo apt update && sudo apt upgradesudo snap install kubectl --classic
sudo snap install helm --classic
sudo apt install nfs-client5.2 Weryfikacja statusu firewalla
Sprawdzamy status firewalla za pomocą jednej z dwóch poniższych komend.
sudo ufw statussudo iptables -v -LWynikiem powinien być komunikat o wyłączonym firewallu.
5.3 Wyłączenie partycji SWAP
Partycja wymiany (SWAP) to systemowa partycja występująca w systemach typu Unix. Służy do tymczasowego przechowywania danych w sytuacji, gdy ich ilość przekracza zasoby wolnej pamięci RAM lub gdy z różnych powodów korzystniej jest przechowywać je (lub ich część) na dysku twardym.
Pierwszą czynnością jest wyłączenie partycji SWAP.
sudo swapoff -aUsuwamy obraz pliku swap i robimy wykomentowanie w pliku fstab, aby nie uruchomił się przy starcie systemu operacyjnego.
sudo rm -f /swap.img
sudo sed -i 's/\/swap.img/#\/swap.img/g' /etc/fstab
Weryfikujemy wykomentowanie za pomocą poniższego polecenia.
sudo cat /etc/fstabRezultatem powinien być wynik podobny do tego poniżej.
5.4 Edycja hosts
Otwieramy plik hosts za pomocą poniższego polecenia.
sudo nano /etc/hostsNależy wkleić poniższe linijki na końcu pliku hosts, zmieniając XXX.XXX.XXX.XXX na odpowiednie adresy IP oraz nazwy hostów. To samo dotyczy wpisów dla load balancera. Nie należy wpisywać hosta, na którym wykonywana jest konfiguracja.
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master1
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master2
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_master3
#loadbalancer
XXX.XXX.XXX.XXX nazwa_loadbalancera_vip5.5 Instalacja RKE2
Instalujemy RKE2 (Rancher Kubernetes Engine 2).
sudo curl -sfL https://get.rke2.io | sudo INSTALL_RKE2_VERSION=v1.34.1+rke2r1 sh -5.6 Uruchomienie RKE2
Uruchamiamy i konfigurujemy usługę RKE2, aby rozpocząć zarządzanie klastrem.
sudo mkdir -p /etc/rancher/rke2/
sudo nano /etc/rancher/rke2/config.yaml#Podaj nazwę loadbalancera VIP i token
server: https://nazwa_loadbalancera_vip:9345
token: Wpisz token uzyskany z pierwszego mastera.
tls-san:
#Podaj nazwę loadbalancera VIP
- "nazwa_loadbalancera_vip"
#zamiast XXX.XXX.XXX.XXX wpisz adresy nodów klastra
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "127.0.0.1"
- "localhost"
#zamiast XXX.XXX.XXX.XXX wpisz adres aktualnego mastera
bind-address:
- "XXX.XXX.XXX.XXX"
advertise-address:
- "XXX.XXX.XXX.XXX"
node-ip:
- "XXX.XXX.XXX.XXX"
#selinux:
# - "true"Następnie uruchamiamy RKE2 na nodzie.
sudo systemctl enable --now rke2-server.serviceW razie problemów z uruchomieniem klastra RKE2, należy wykonać poniższą komendę, aby sprawdzić logi.
journalctl -u rke2-server.service -f5.7 Dodanie uprawnień dla kubectl
Aby skonfigurować dostęp dla kubectl, należy wykonać poniższe polecenia:
mkdir .kube
sudo cp /etc/rancher/rke2/rke2.yaml .kube/config
sudo chmod 600 .kube/config
sudo chown $USER .kube/configNastępnie ustawiamy zmienną środowiskową KUBECONFIG, aby kubectl korzystał z odpowiedniego pliku.
export KUBECONFIG=.kube/configZa pomocą poniższego polecenia sprawdzamy, czy kubectl działa.
kubectl get nodes
Dla większej liczby masterów, wyglądałoby to tak, jak poniżej.

Krok 6. Konfiguracja kolejnych nodów (worker 1, worker 2 itd.)
6.1 Aktualizacja systemu oraz instalacja narzędzi
Zanim rozpoczniemy instalację narzędzi, należy upewnić się, że system jest w pełni zaktualizowany. W tym celu uruchamiamy poniższe polecenie:
sudo apt update && sudo apt upgradesudo snap install kubectl --classic
sudo snap install helm --classic
sudo apt install nfs-client6.2 Weryfikacja statusu firewalla
Sprawdzamy status firewalla za pomocą jednej z dwóch poniższych komend.
ufw statusiptables -v -LWynikiem powinien być komunikat o wyłączonym firewallu.
6.3 Wyłączenie partycji SWAP
Partycja wymiany (SWAP) to systemowa partycja występująca w systemach typu Unix. Służy do tymczasowego przechowywania danych w sytuacji, gdy ich ilość przekracza zasoby wolnej pamięci RAM lub gdy z różnych powodów korzystniej jest przechowywać je (lub ich część) na dysku twardym.
Pierwszą czynnością jest wyłączenie partycji SWAP.
swapoff -aUsuwamy obraz pliku swap i robimy wykomentowanie w pliku fstab, aby nie uruchomił się przy starcie systemu operacyjnego.
rm -f /swap.img
sed -i 's/\/swap.img/#\/swap.img/g' /etc/fstab
Wykomentowanie należy zweryfikować.
cat /etc/fstabRezultatem powinien być wynik podobny do tego poniżej.
6.4 Edycja hosts
Otwieramy plik hosts za pomocą poniższego polecenia.
sudo nano /etc/hostsNależy wkleić poniższe linijki na końcu pliku hosts, zmieniając XXX.XXX.XXX.XXX na odpowiednie adresy IP oraz nazwy hostów. To samo dotyczy wpisów dla load balancera. Nie należy wpisywać hosta, na którym wykonywana jest konfiguracja.
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_nod1
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_nod2
XXX.XXX.XXX.XXX nazwa_serwera_aplikacyjnego_nod3
#loadbalancer
XXX.XXX.XXX.XXX nazwa_domenowa_loadbalancera6.5 Instalacja RKE2
Instalujemy RKE2 (Rancher Kubernetes Engine 2).
sudo curl -sfL https://get.rke2.io | sudo INSTALL_RKE2_VERSION=v1.34.1+rke2r1 INSTALL_RKE2_TYPE="agent" sh -6.6 Uruchomienie RKE2
Uruchamiamy i konfigurujemy usługę RKE2, aby rozpocząć zarządzanie klastrem.
Utworzenie folderu i pliku konfiguracyjnego dla klastra.
sudo mkdir -p /etc/rancher/rke2/
sudo nano /etc/rancher/rke2/config.yaml#Podaj nazwę loadbalancera VIP i token
server: https://nazwa_loadbalancera_vip:9345
token: Wpisz token uzyskany z pierwszego mastera.
tls-san:
- "nazwa_loadbalancera_vip"
#zamiast XXX.XXX.XXX.XXX wpisz adresy nodów klastra
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "XXX.XXX.XXX.XXX"
- "127.0.0.1"
- "localhost"
#zamiast XXX.XXX.XXX.XXX wpisz adres aktualnego master
bind-address:
- "XXX.XXX.XXX.XXX"
advertise-address:
- "XXX.XXX.XXX.XXX"
node-ip:
- "XXX.XXX.XXX.XXX"
#selinux:
# - "true"Następnie uruchamiamy RKE2 na nodzie.
sudo systemctl enable --now rke2-agent.serviceW razie problemów z uruchomieniem klastra RKE2, należy wykonać poniższą komendę, aby sprawdzić logi.
journalctl -u rke2-agent.service -f6.7 Weryfikacja poprawności działania masterów
Na Master 1 sprawdzamy, czy liczba nodów jest poprawna. Można to zrobić za pomocą polecenia kubectl lub, opcjonalnie, w statystykach HAProxy.
kubectl get nodes
Krok 7. Instalacja Ranchera
Przechodzimy na serwer docelowy, na którym zostanie zainstalowana aplikacja Rancher do zarządzania klastrem Kubernetes.
7.1 Przełączenie się na konto roota
Wszystkie czynności należy wykonywać z uprawnieniami użytkownika root. Aby przełączyć się na konto root, używamy poniższego polecenia:
sudo su -7.2 Aktualizacja systemu oraz instalacja narzędzi
Przed kontynuowaniem instalacji Ranchera należy się upwenić, że system jest w pełni zaktualizowany. W tym celu wykonujemy następujące polecenie:
apt update && sudo apt upgrade7.3 Instalacja Dockera
Docker to popularna platforma typu open source służąca do realizacji wirtualizacji na poziomie systemu operacyjnego (tzw. konteneryzacji). Kontener Docker jest lekkim, autonomicznym i wykonywalnym kontenerem, który zawiera wszystko, co jest potrzebne do uruchomienia aplikacji (biblioteki, narzędzia systemowe, kod i środowisko uruchomieniowe). Kontenery upraszczają dostarczanie rozproszonych aplikacji i stają się coraz popularniejsze w miarę jak organizacje coraz częściej wykorzystują hybrydowe środowiska wielochmurowe. Więcej informacji na oficjalnej stronie Dockera.
W pierwszej kolejności należy pobrać Dockera.
curl -fsSL https://get.docker.com -o get-docker.shUruchamiamy instalację Dockera.
sh get-docker.shPo poprawnej instalacji otrzymamy komunikat jak niżej.
7.4 Instalacja aplikacji
Przełączamy się na konto root.
sudo su -Następnie uruchamiamy Ranchera przy użyciu Dockera.
docker run -d --restart=unless-stopped --name rancher -p 8081:80 -p 8443:443 --privileged rancher/rancher:v2.12.3Po prawidłowej instalacji pojawi się odpowiedni komunikat.

7.5 Uzyskanie hasła startowego do Ranchera
Aby uzyskać hasło startowe do Ranchera, należy użyć poniższej komendy.
docker logs rancher 2>&1 | grep "Bootstrap Password:"Powinien się wyświetlić komunikat zawierający hasło.

Jeżeli nie widzimy komunikatu z hasłem, oznacza to, że Rancher jeszcze się nie uruchomił. Trzeba spróbować za chwilę ponownie, a następnie skopiować wyświetlone hasło startowe do Ranchera.
7.6 Uruchomienie, konfiguracja oraz instalacja EZD RP w Rancherze
Czysta instalacja serwera Ubuntu nie ma uruchomionego firewalla. Zainstalowany Rancher dostępny będzie pod adresem: https://ip_serwera:8443. Po zaakceptowaniu certyfikatu wyświetli się strona strona powitalna Ranchera. Wklejamy wcześniej skopiowane hasło i logujemy się.
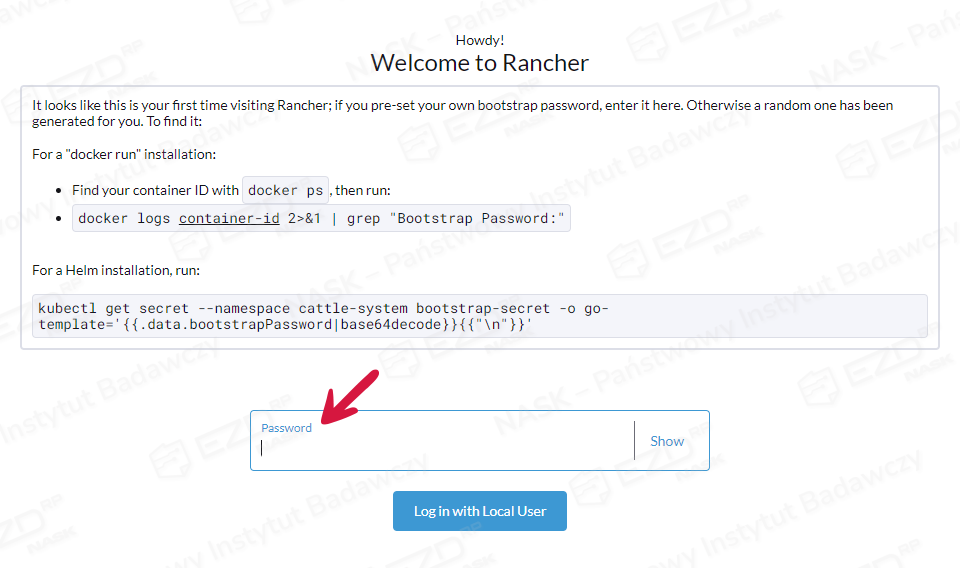
Następnie ustalamy swoje nowe hasło.
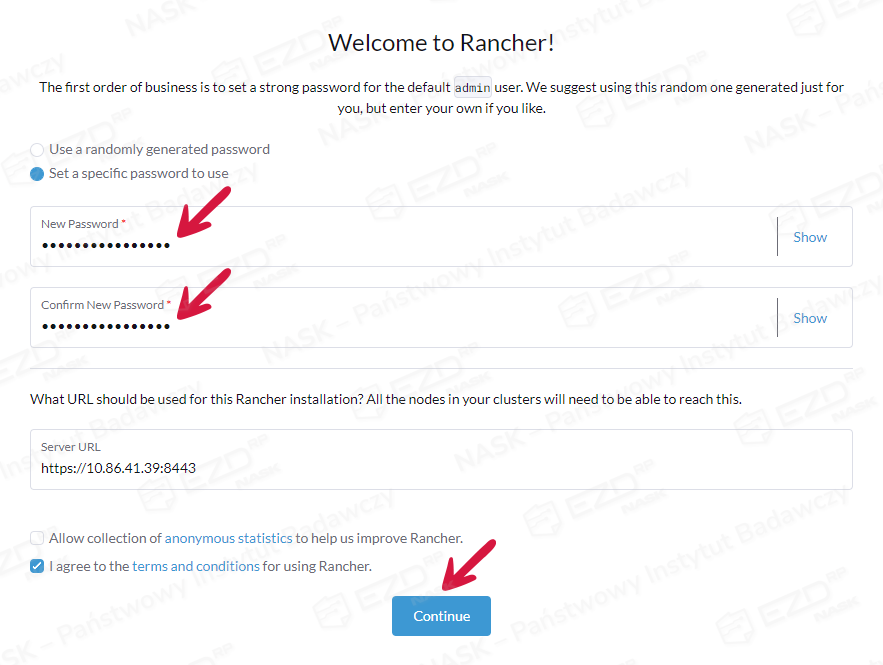
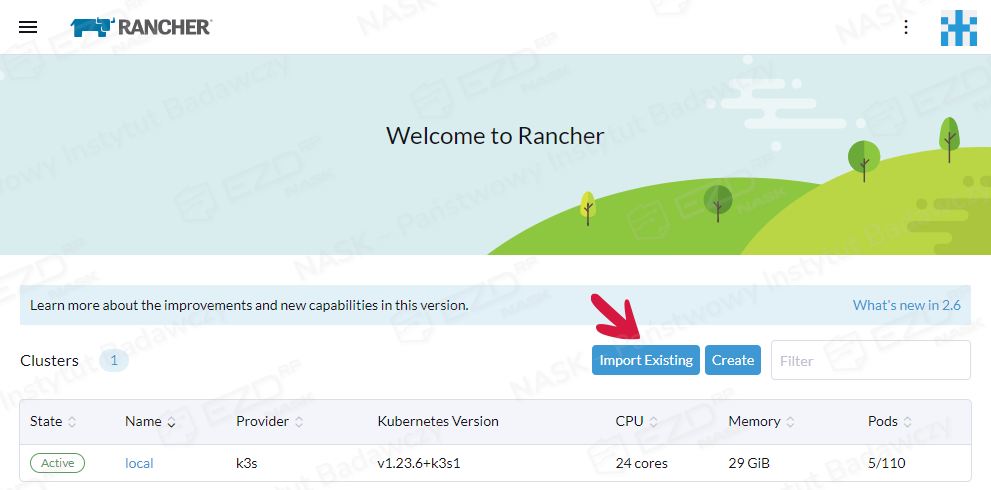
Po uruchomieniu Rancher pokazuje jeden aktywny klaster lokalny. Następny krok to dodanie nowego klastra, którym chcemy zarządzać za pomocą Ranchera. Klikamy Import Existing > Generic > wpisujemy nazwę klastra > Create
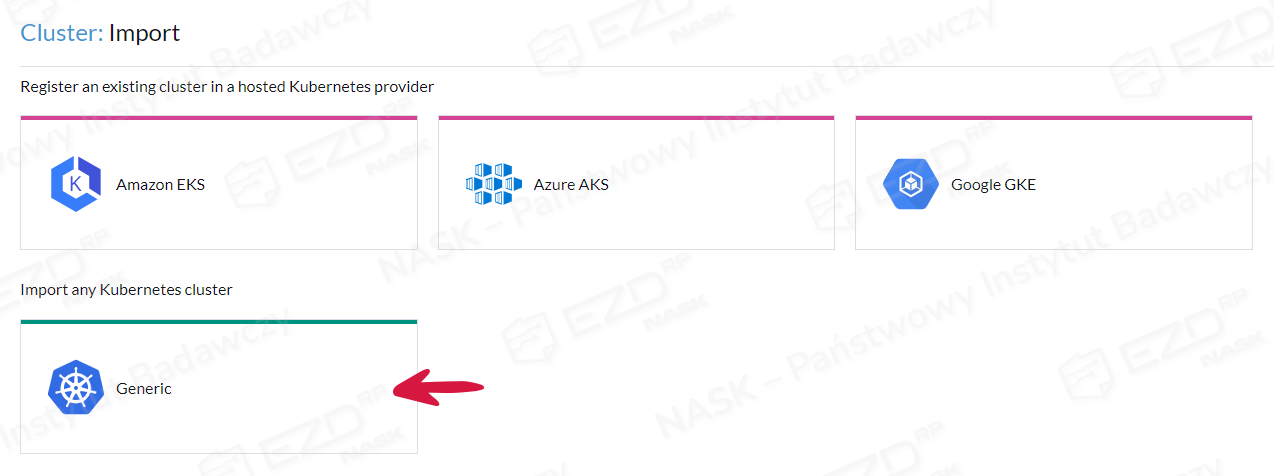
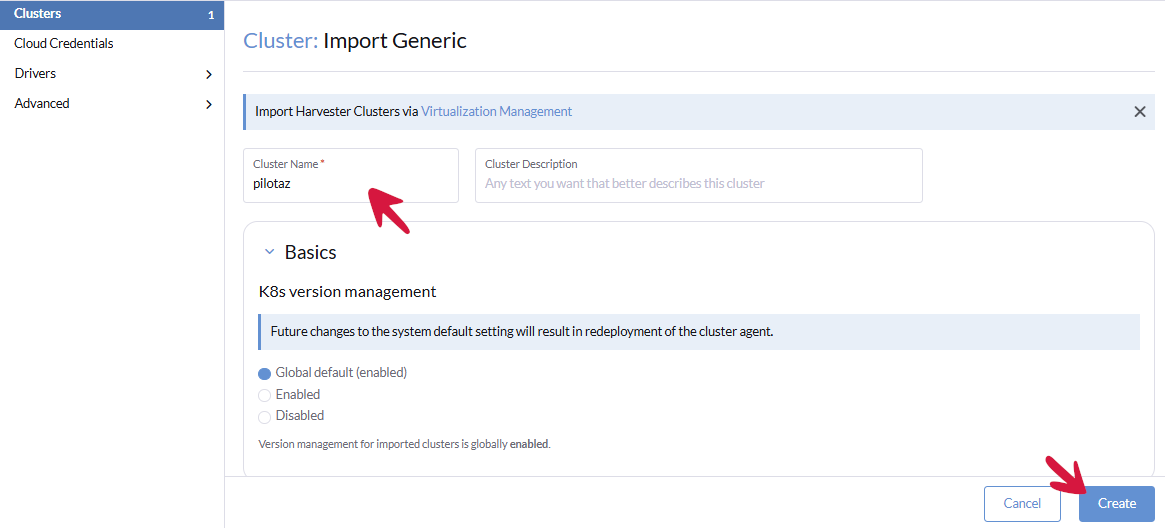
Uruchomi się kreator dodawania nowego klastra z nadanym statusem Pending. Rrancher czeka na zgłoszenie się nowego klastra, który można dodać na kilka sposobów, przedstawionych na poniższym ekranie. Wybieramy drugi sposób – z wykorzystaniem polecenia curl. Kopiujemy całe polecenie, wklejamy je do konsoli serwera Ubuntu na serwerze Master 1 i wykonujemy jako użytkownik root.
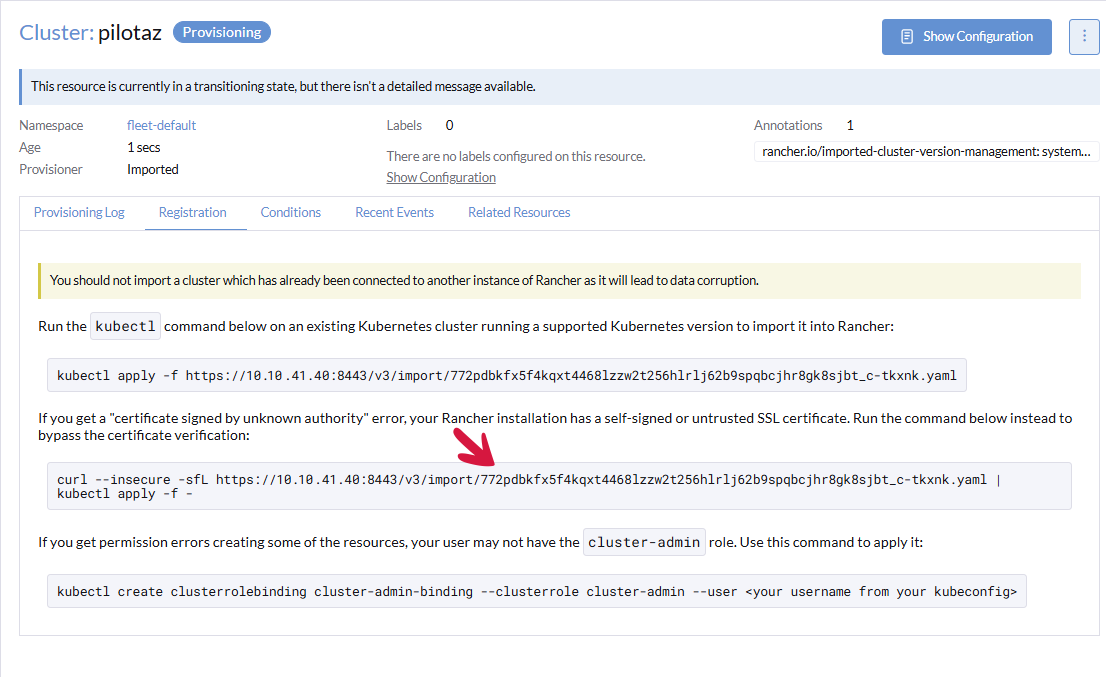
Po wklejeniu polecenia otrzymamy infomację jak niżej.

Po około 1-5 min status klastra zmieni się z Waiting na Active.


Przechodzimy do nowo uruchomionego klastra. Rozwijamy główne menu dostępne w lewym górnym rogu i wybieramy dodany klaster. W naszym przykładzie nosi on nazwę pilotaz.
Aby dodać do systemu repozytoria, należy wybrać zakładkę Apps > Repositories, a następnie kliknąć przycisk Create.
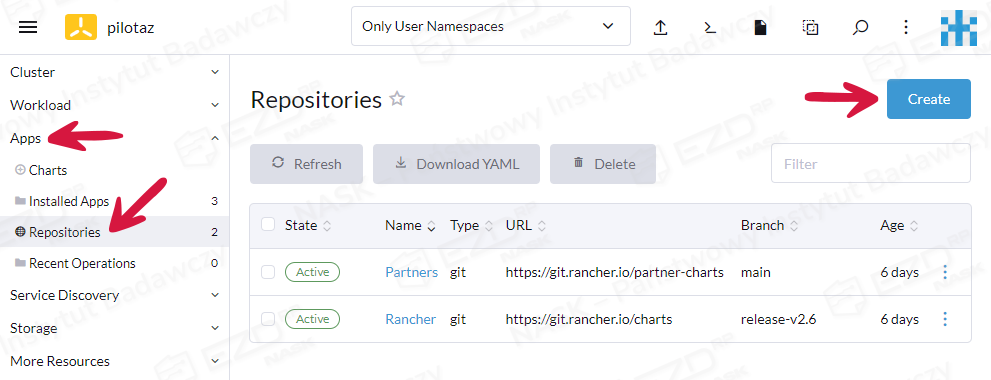
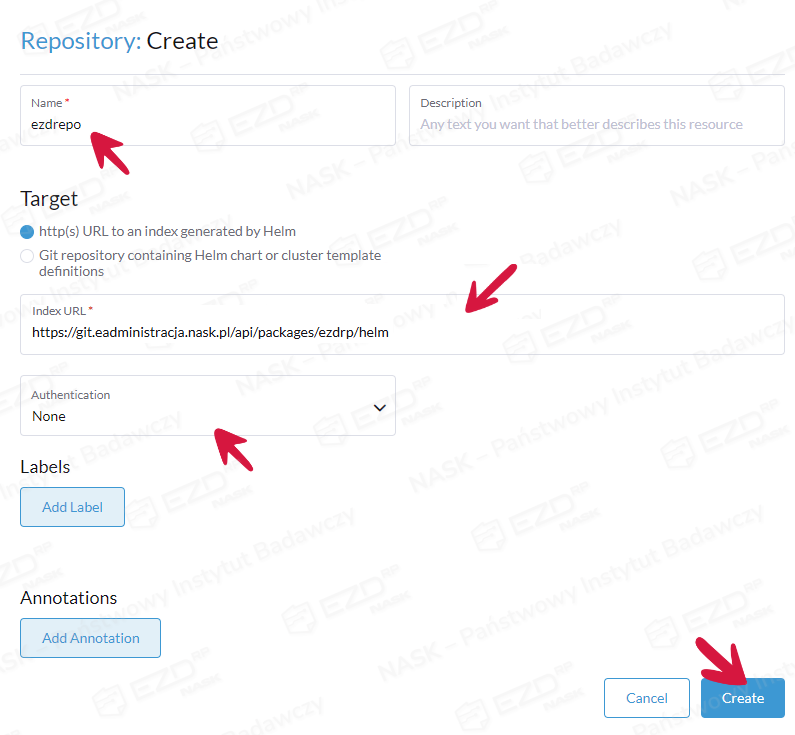
Dodajemy dwa repozytoria, wypełniając pola w przedstawiony niżej sposób:
Name: dowolna nazwa, np. ezdrepo
Index URL: https://git.eadministracja.nask.pl/api/packages/ezdrp/helm
Authentication: None
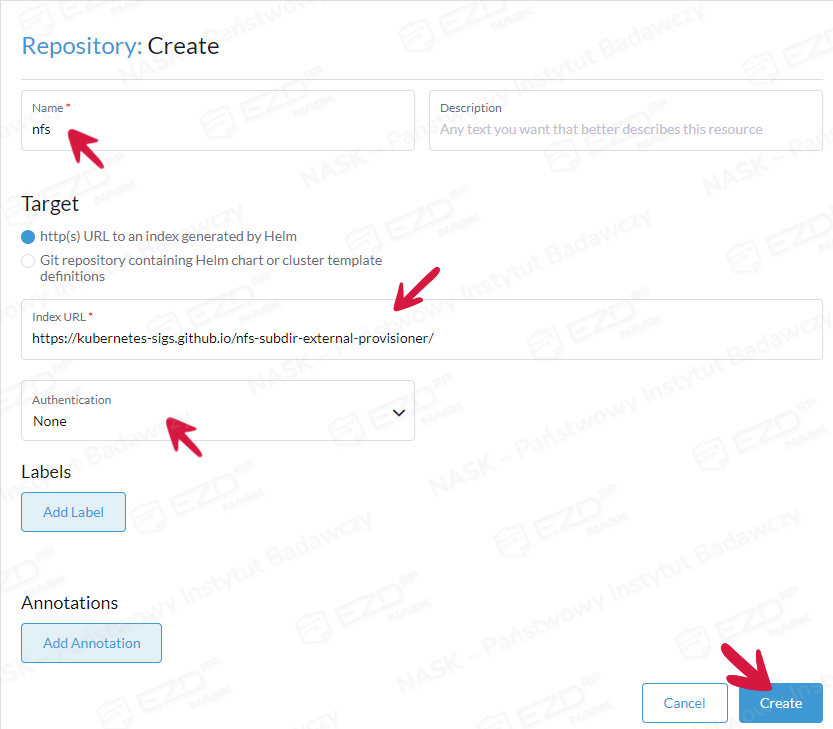
Name: dowolna nazwa, np. nfs
Index URL: https://kubernetes-sigs.github.io/nfs-subdir-external-provisioner/
Authentication: None (jest to repozytorium publiczne i nie wymaga logowania)
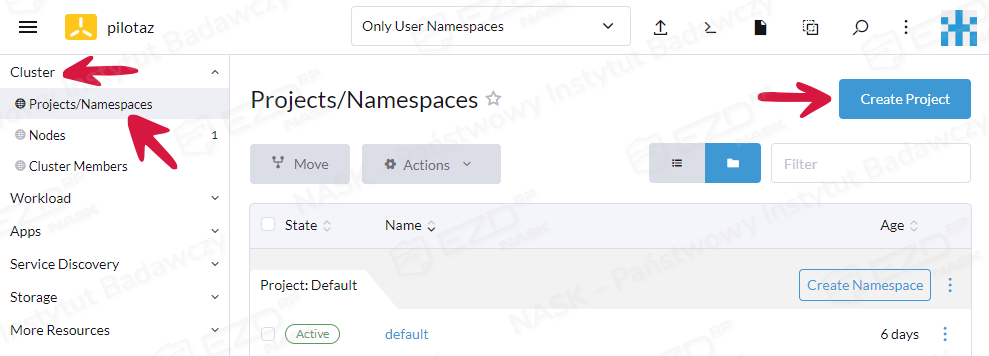
Po dodaniu repozytoriów należy utworzyć nowy projekt, a w nim nową przestrzeń nazw. W tym celu wybieramy zakładkę Cluster > Projects/Namespaces i klikamy przycisk Create Project.
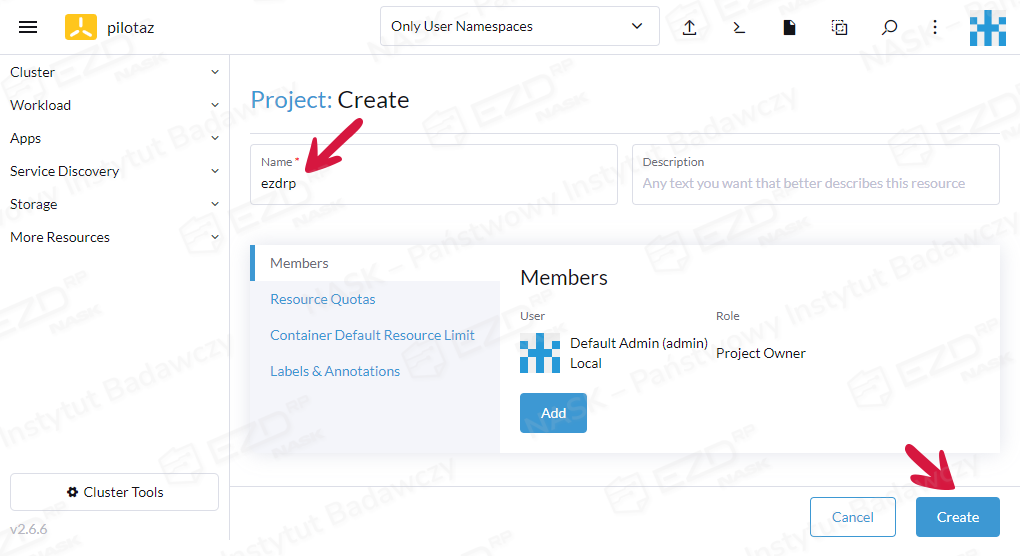
Podajemy nazwę nowego projektu, np. ezdrp i klikamy przycisk Create.
W głównym oknie na dole wyświetli się nasz nowo utworzony projekt. Należy kliknąć znajdujący się przy nim przycisk Create Namespace.
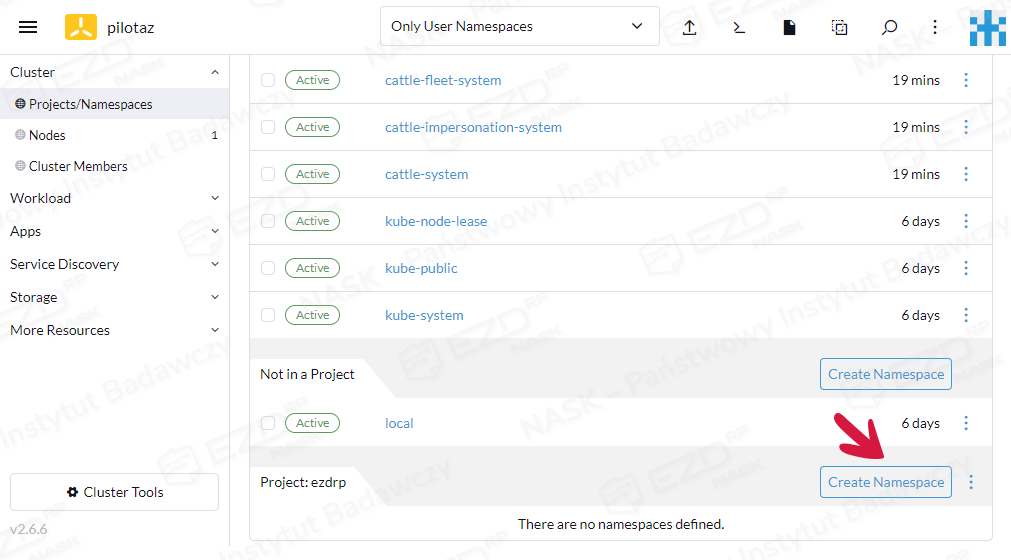
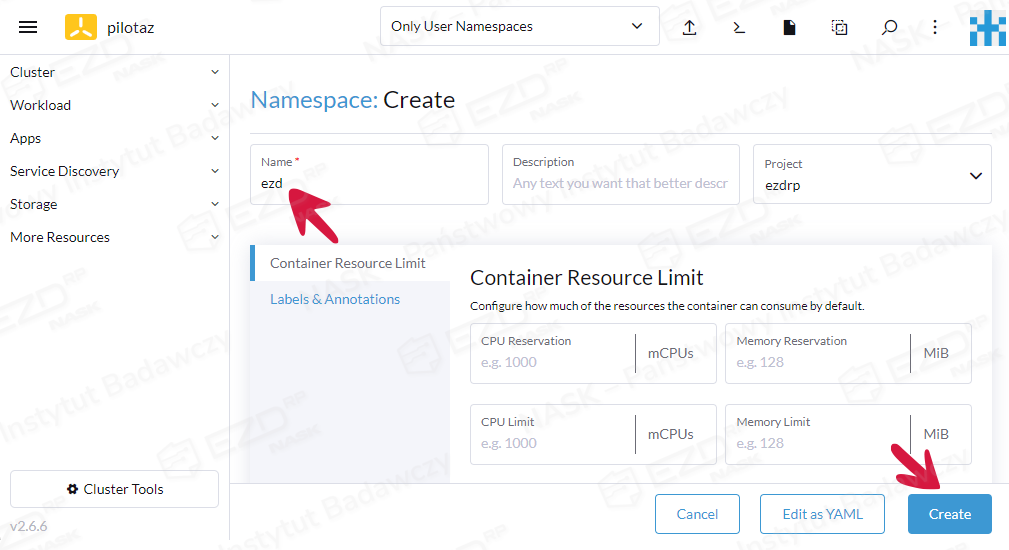
Podajemy nazwę nowej przestrzeni nazw, np. ezd i klikamy przycisk Create.
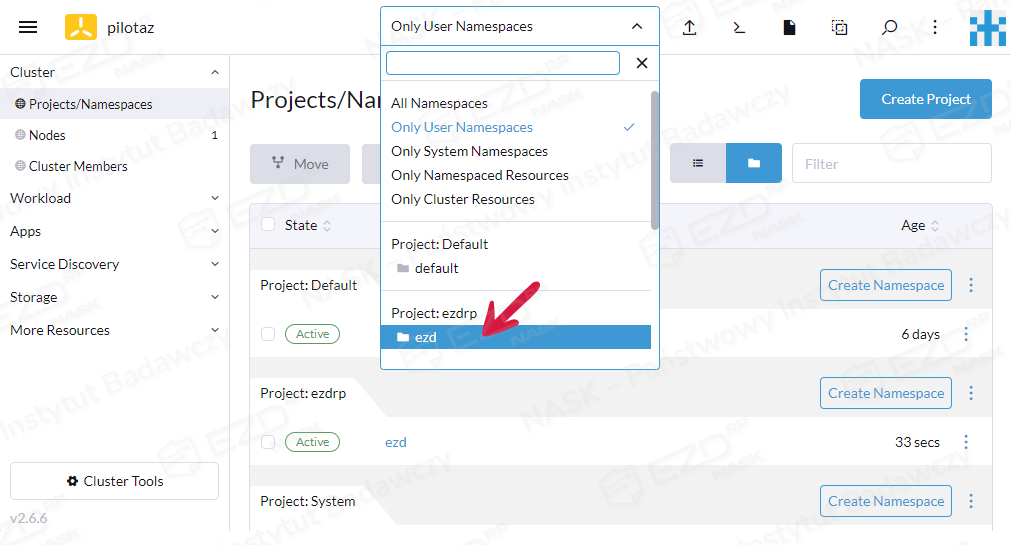
Aby przejść do dalszych czynności, należy rozwinąć listę dostępną w górnym menu i wskazać utworzony przez nas projekt oraz przestrzeń nazw.
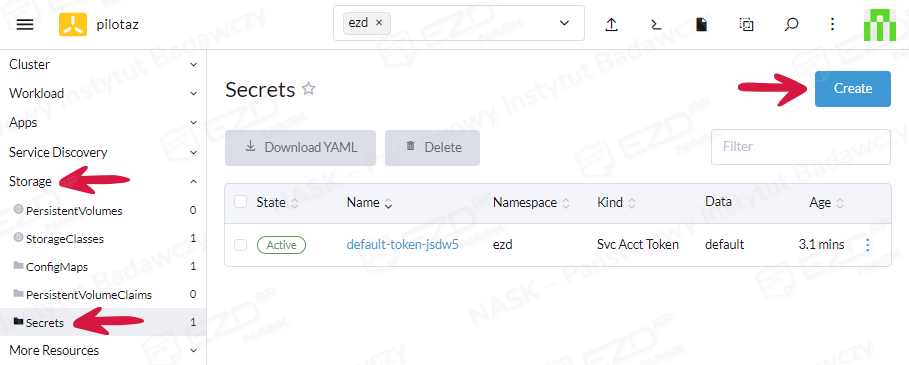
Następnie wybieramy zakładkę Storage > Secrets i klikamy przycisk Create.
Wybieramy TLS Certificate.
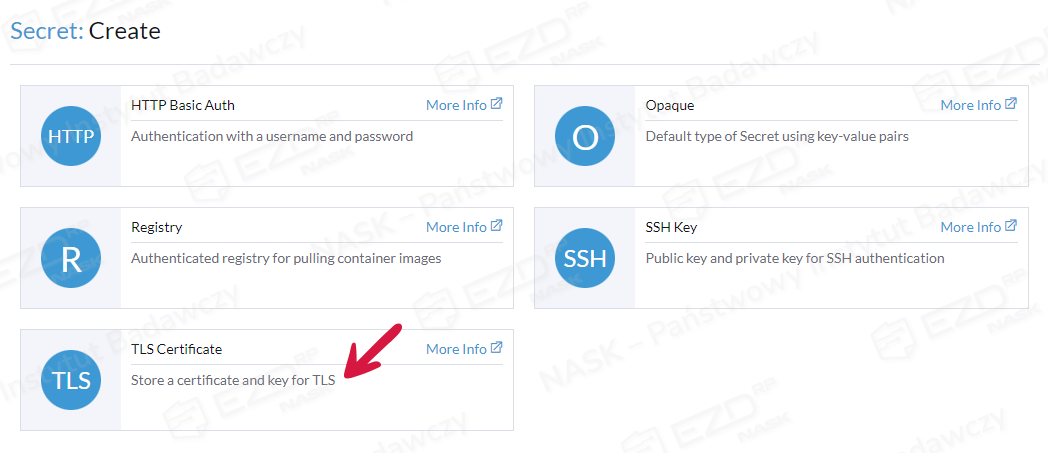
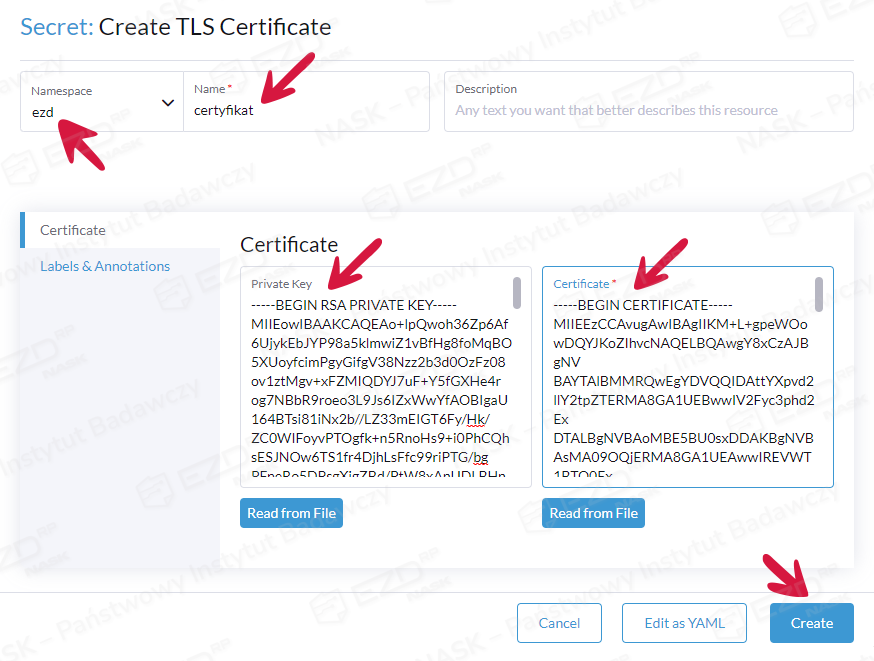
W wyświetlonym oknie wprowadzamy nazwę „certyfikat”, po lewej stronie formularza wprowadzamy klucz prywatny, natomiast po prawej publiczny (certyfikat bez CA/ROOT).
—–BEGIN PRIVATE KEY—–
—–BEGIN RSA PRIVATE KEY—–
Nieobsługiwany to:
—–BEGIN ENCRYPTED PRIVATE KEY—–

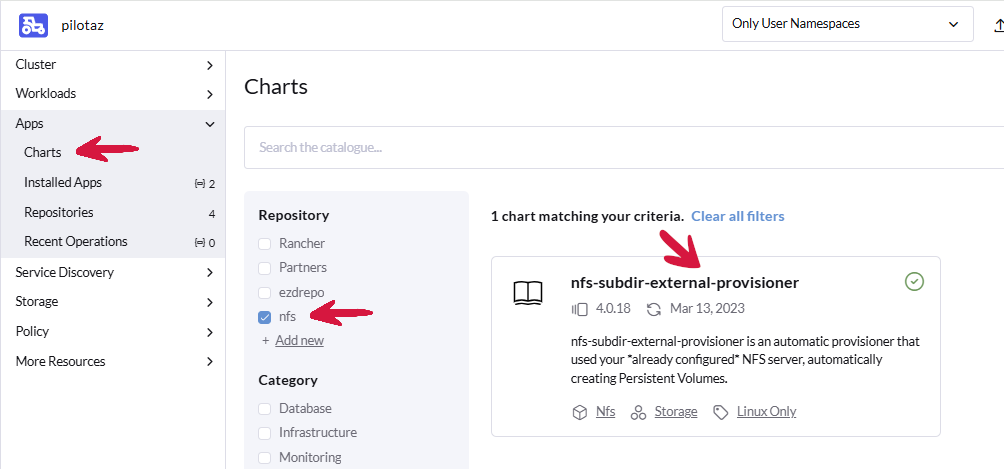
7.7.1. Instalacja NFS konektor
Klikamy zakładkę Apps > Charts, a następnie w polu filtrowania wpisujemy nfs. Wybieramy pozycję nfs-subdir-external-provisioner.
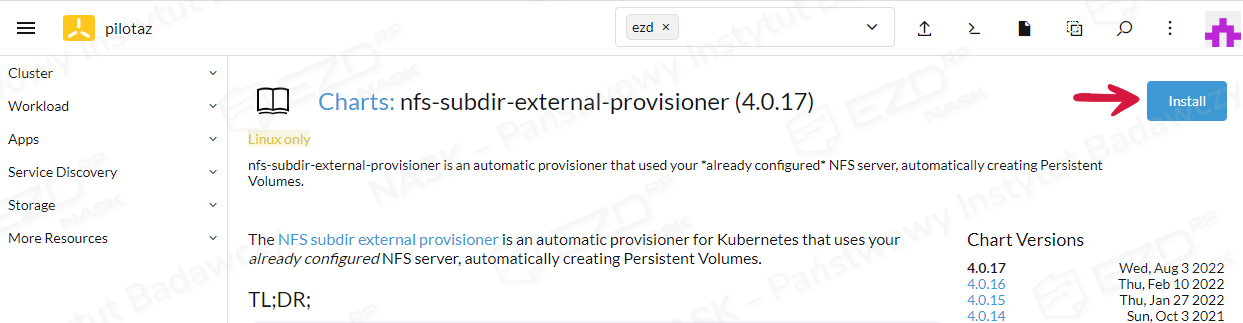
Wybieramy najnowszą wersję aplikacji i klikamy przycisk Install.
W polu Name wpisujemy dowolną nazwę, np. nfs i klikamy przycisk Next.
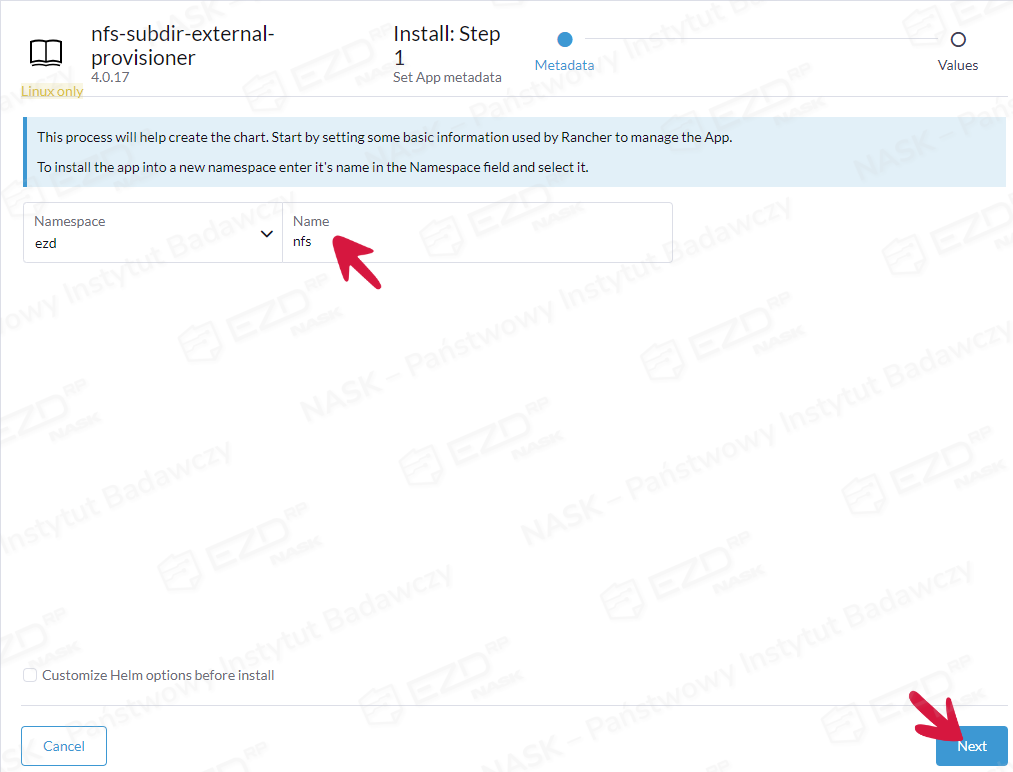
W Edit YAML edytujemy linijkę z path: wpisując nazwę folderu w naszym przypadku /nfs.
Dodatkowo edytujemy linijkę z server: wpisując IP serwera NFS i klikamy przycisk Install.
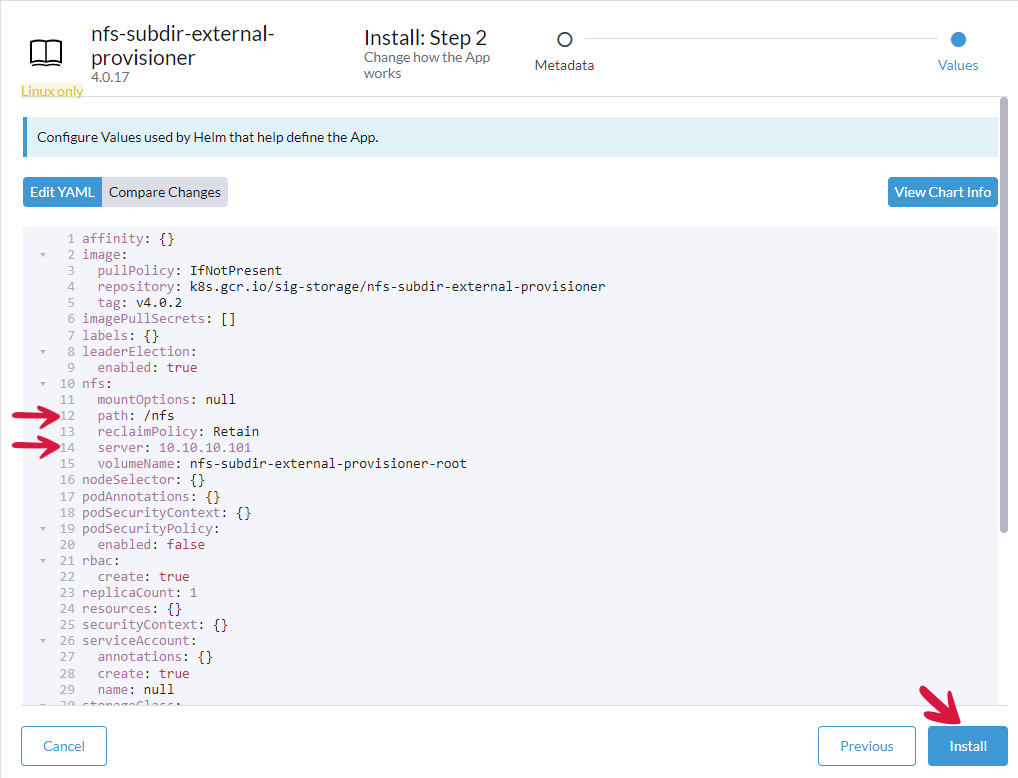
Po wykonananej prawidłowo instalacji należy wykonać test, przechodząc do Storage > PersistentVolumeClaims
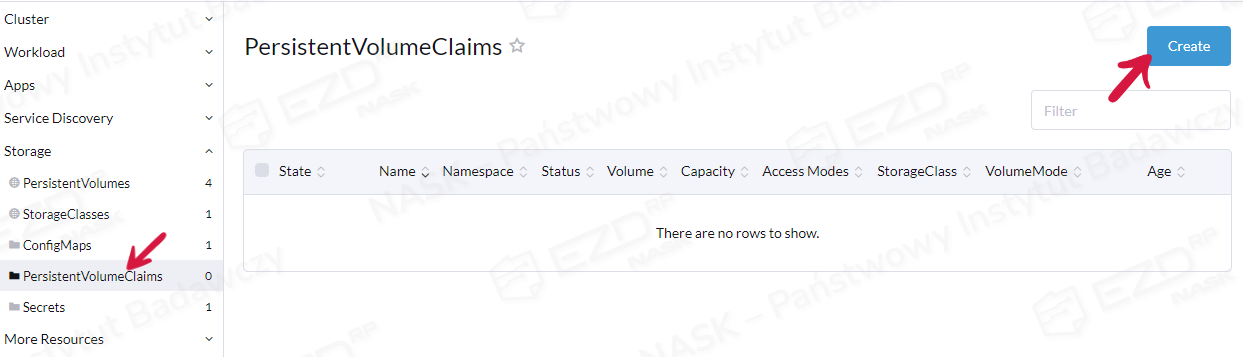
W polu Name wpisujemy dowolną nazwę, przykładowo test, w Storage Class wybieramy nfs-client, a w Request Storage wpisujemy 1 i klikamy przycisk Create
Następnie przechodzimy na serwer NFS i sprawdzamy, czy w naszym folderze pojawiło się PVC.

7.7.2 Weryfikacja storage
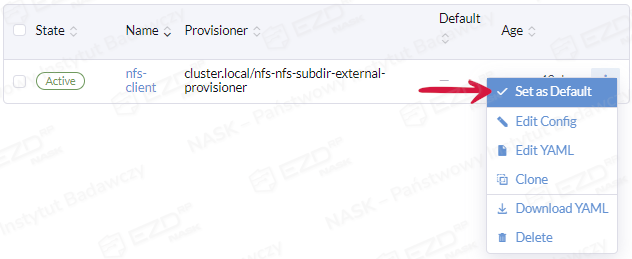
Przechodzimy do zakładki Storage > StorageClasses. Po prawej stronie przy pozycji nfs-client klikamy symbol trzech kropek, a następnie wybieramy opcję Set as Default.
7.7.3. Instalacja EZD RP
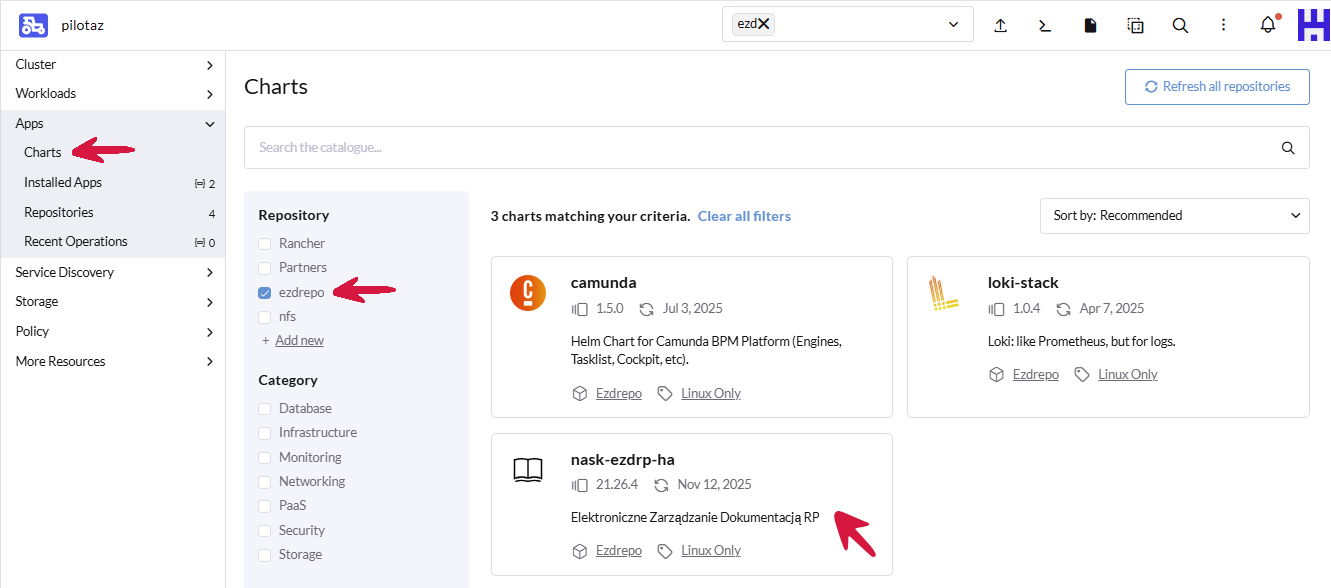
Klikamy zakładkę Apps > Charts, a następnie w polu filtrowania wpisujemy ezd.
Wybieramy pozycję nask-ezdrp-ha.
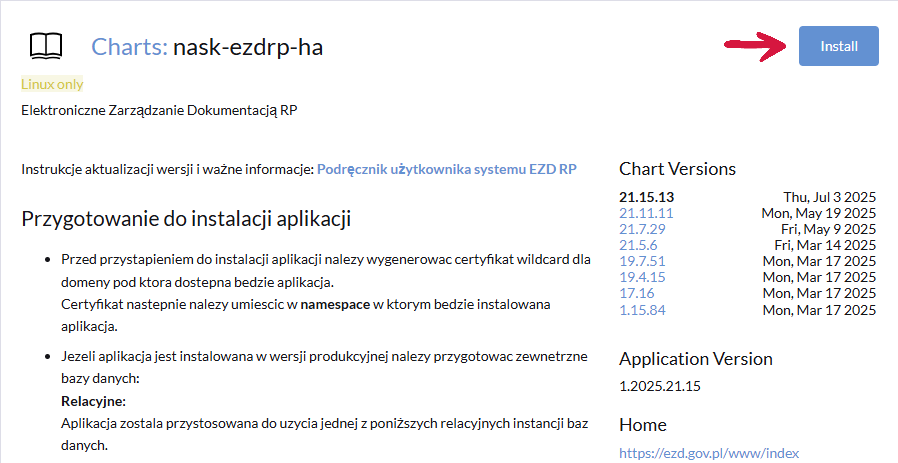
Wskazujemy najnowszą wersję aplikacji i klikamy przycisk Install.
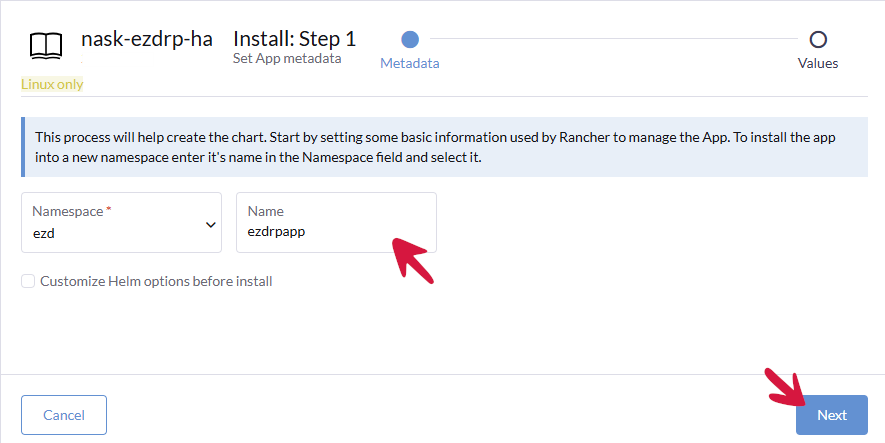
W polu Name wpisujemy dowolną nazwę, np. ezdrpapp i klikamy przycisk Next.
Klikamy zakładkę Domain Info, a następnie wpisujemy nazwę domeny (dla której został wygenerowany wcześniej certyfikat), w polu poniżej zostawiamy nazwę „certyfikat” i odznaczamy „Snippets Annotations”.
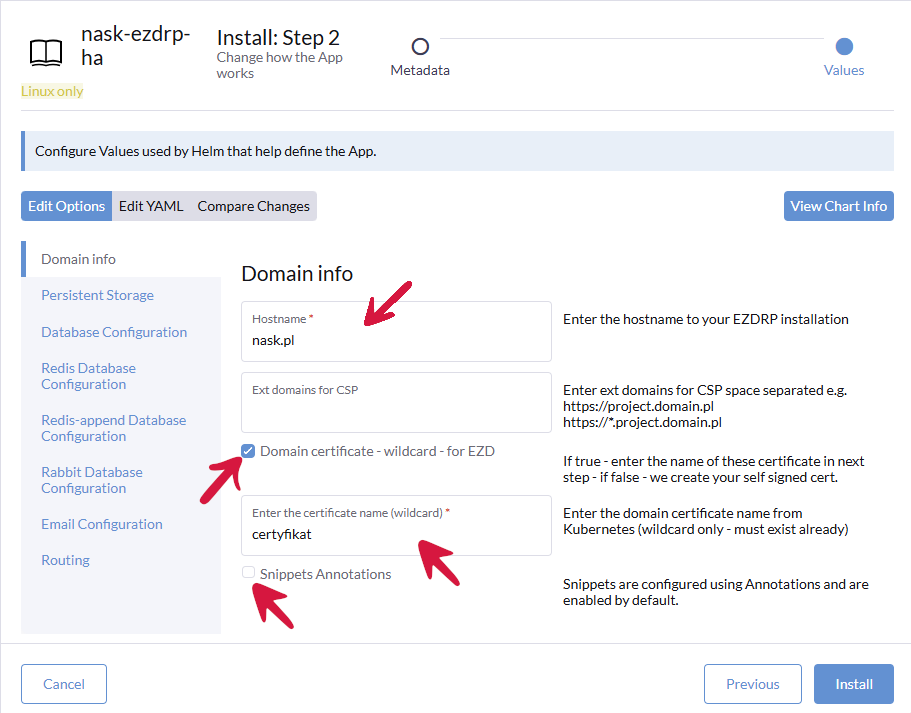
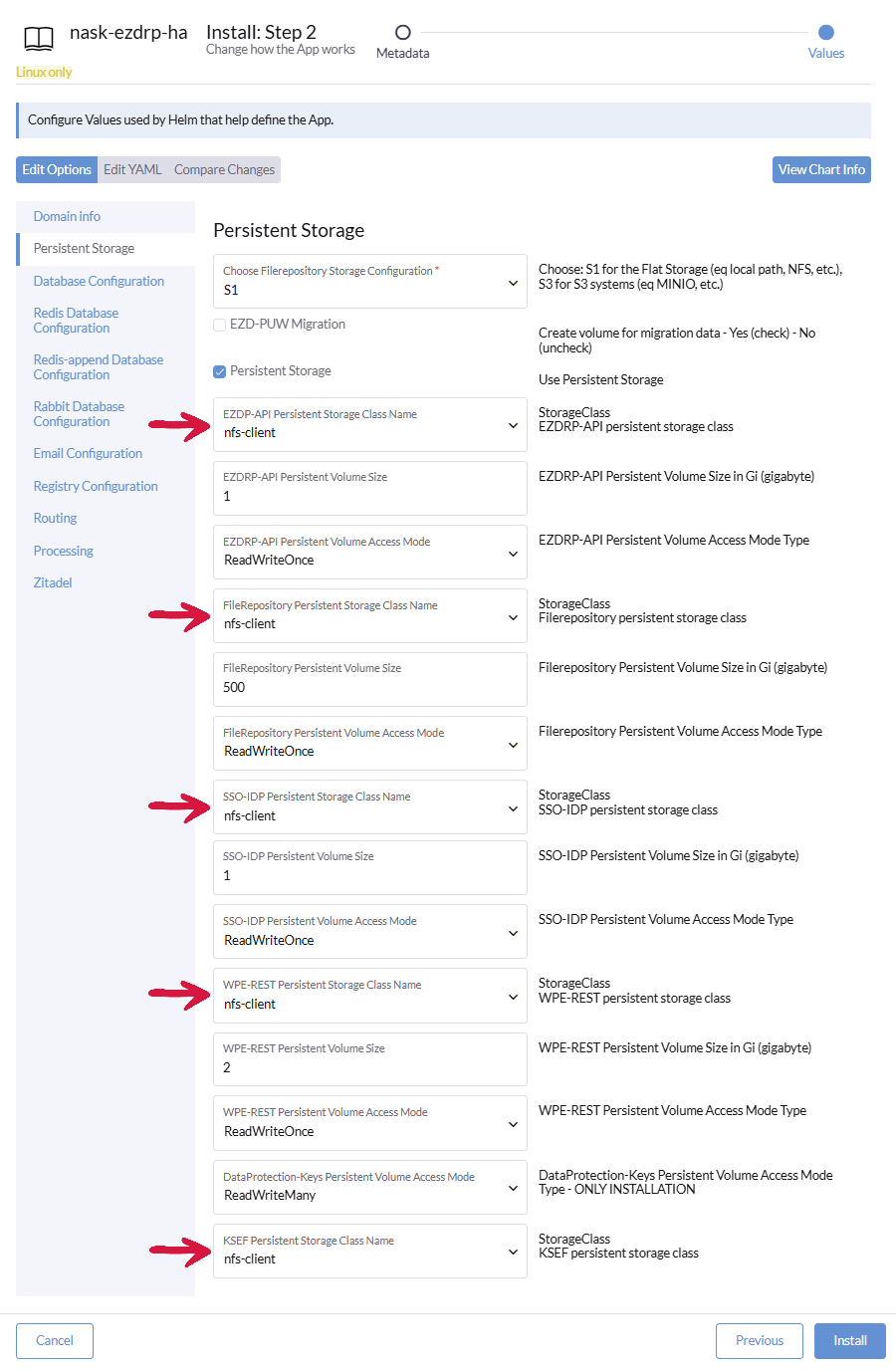
Klikamy zakładkę Persistent Storage i we wszystkich polach z rozwijaną listą zmieniamy ustawienie z longhorn na nfs-client.
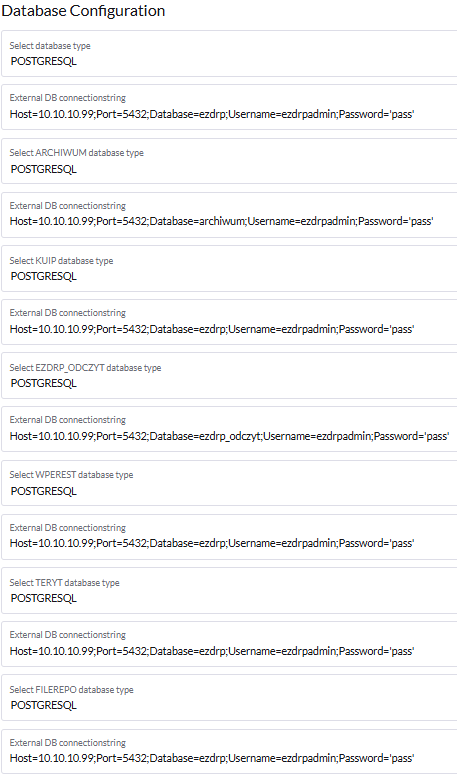
W zakładce Database configuration wybieramy, z jakiego rodzaju bazą będziemy się łączyć (w naszym przypadku będzie to PostgreSQL) i wklejamy connection strings.
Connection string dla EZDRP
Host=x.x.x.x;Port=5432;Database=ezdrp;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla ARCHIWUM:
Host=x.x.x.x;Port=5432;Database=archiwum;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla KUIP
Host=x.x.x.x;Port=5432;Database=ezdrp;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla EZDRP_ODCZYT:
Host=x.x.x.x;Port=5432;Database=ezdrp_odczyt;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla WPEREST
Host=x.x.x.x;Port=5432;Database=ezdrp;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla TERYT
Host=x.x.x.x;Port=5432;Database=ezdrp;Username=uzytkownik_postgres;Password='haslo_postgres'Connection string dla FILEREPO
Host=x.x.x.x;Port=5432;Database=ezdrp;Username=uzytkownik_postgres;Password='haslo_postgres'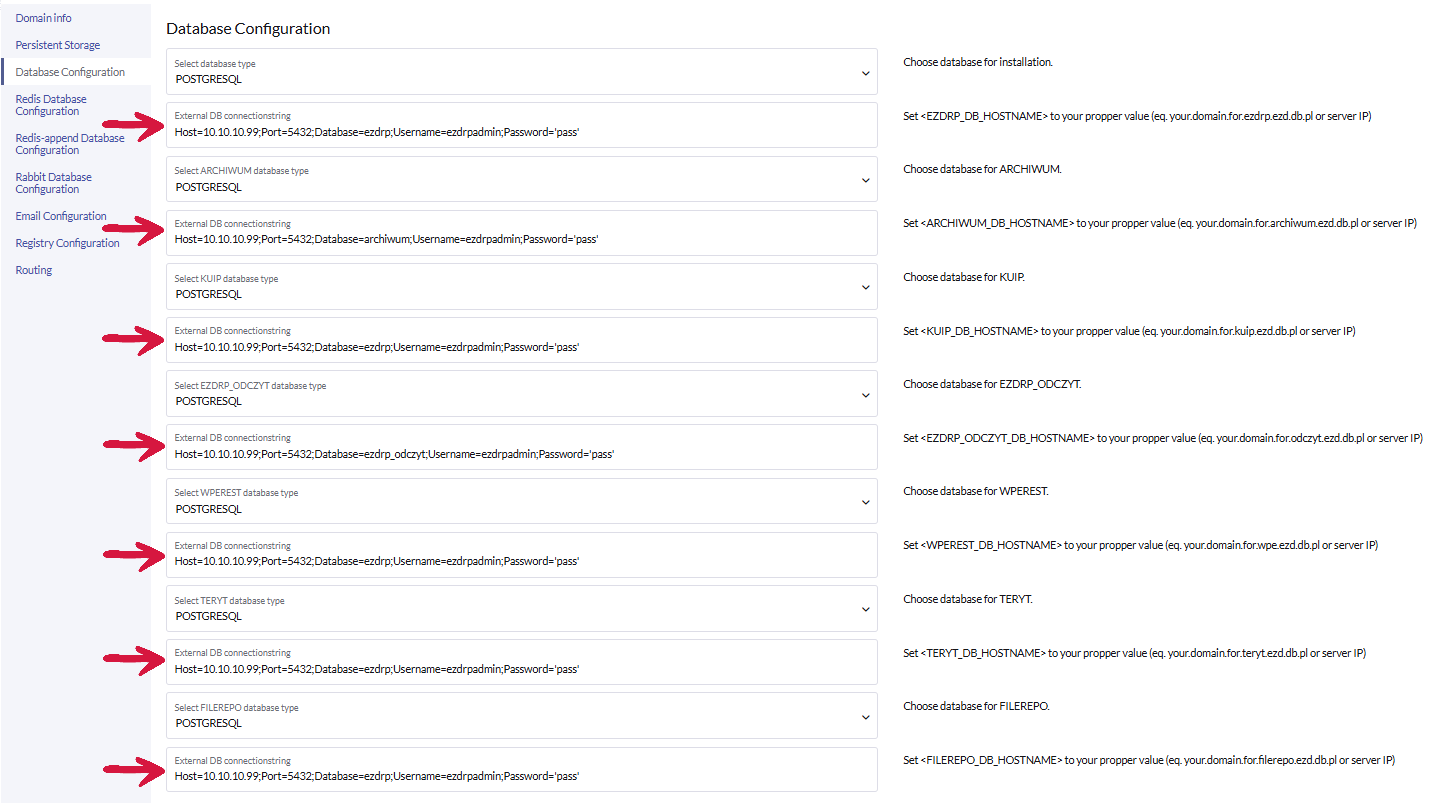
Klikamy zakładkę Redis Database Configuration, a następnie w odpowiednich polach podajemy adres IP serwera Redis i hasło.
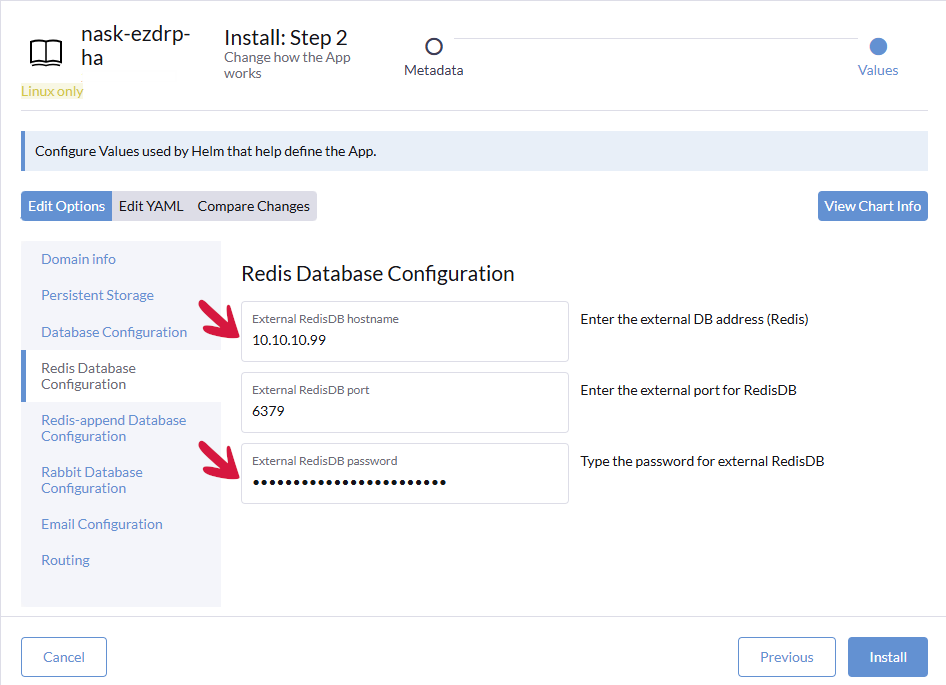
Klikamy zakładkę Redis-append Database Configuration, a następnie w odpowiednich polach podajemy adres IP serwera Redis i hasło.
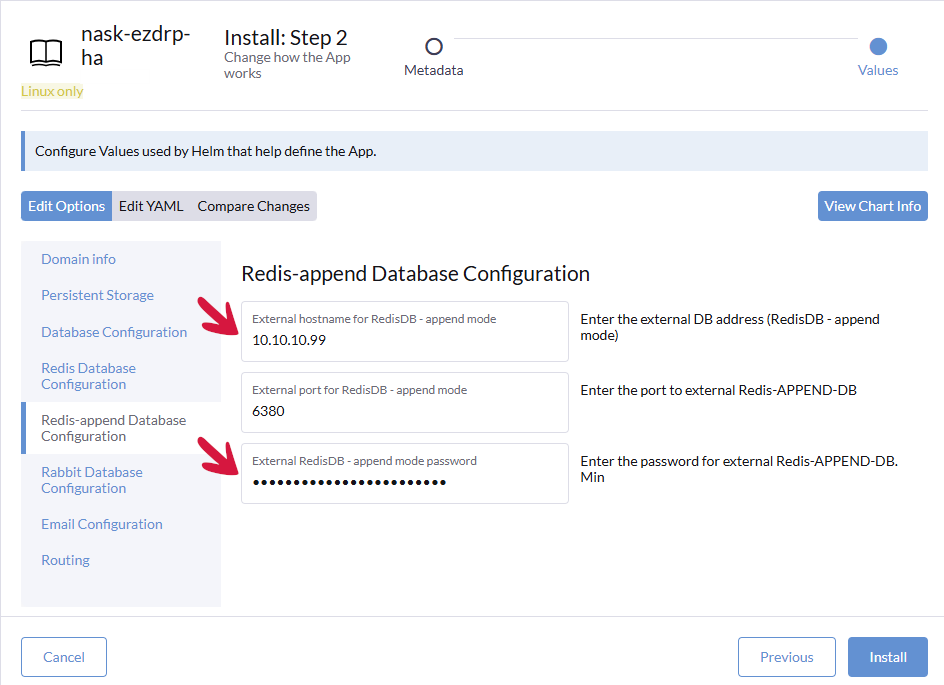
Klikamy zakładkę Rabbit Database Configuration, a następnie w odpowiednich polach podajemy adres IP serwera Rabbit, nazwę użytkownika oraz hasło.
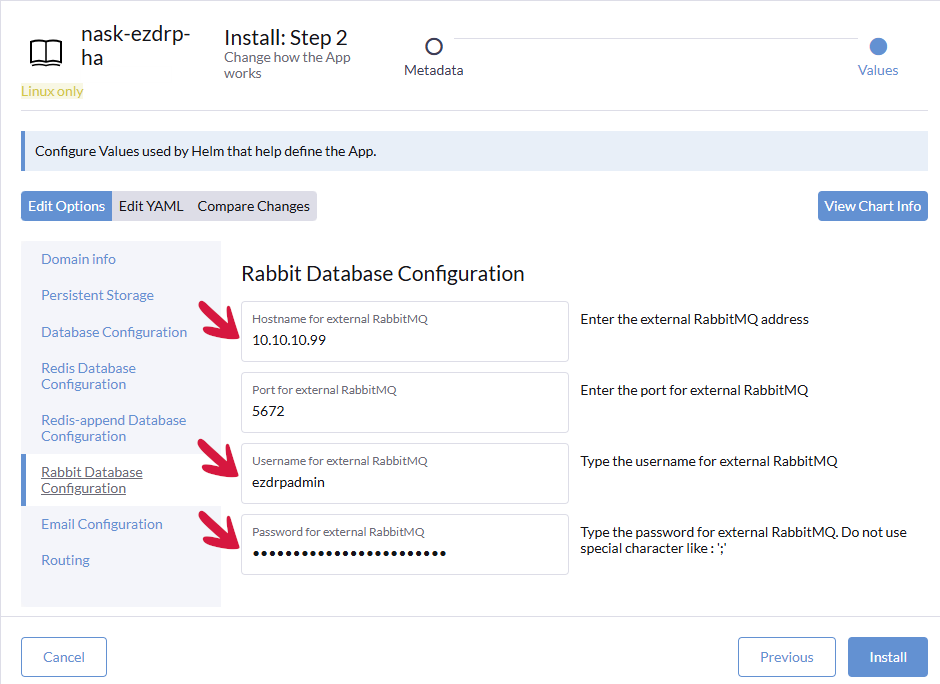
Klikamy zakładkę Email Configuration, a następnie zaznaczamy pole wyboru przy opcji Mail server for project i wpisujemy w polach dane systemu pocztowego.
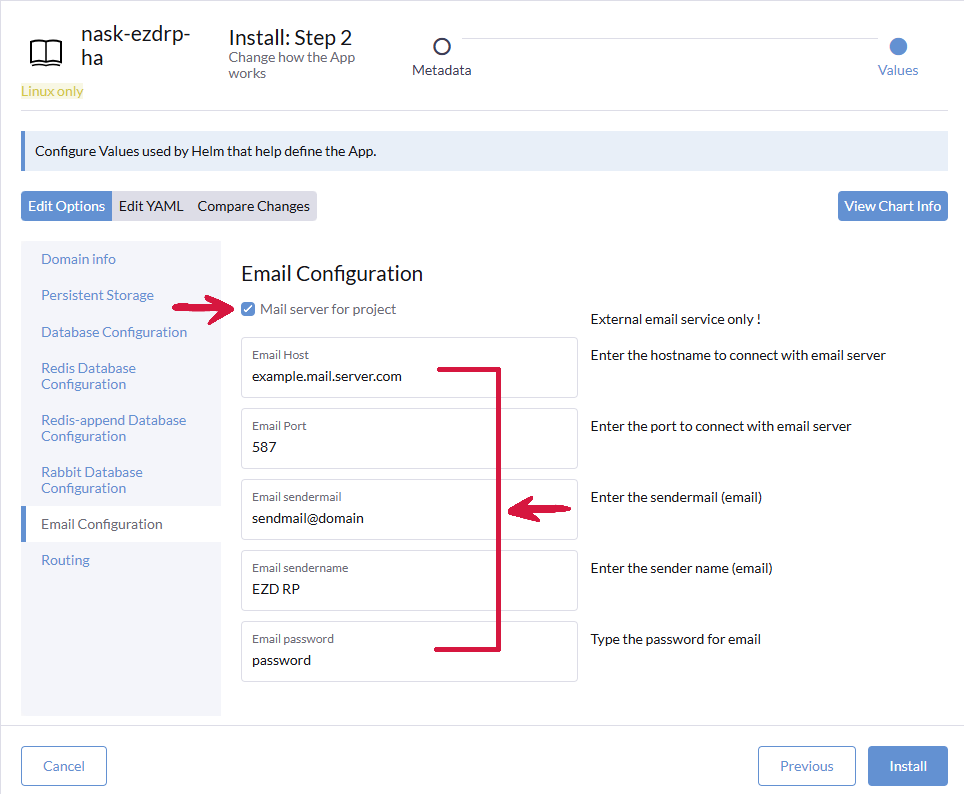
Klikamy zakładkę Routing, upewniamy się by polu Select routing type jest wybrana opcja ingress
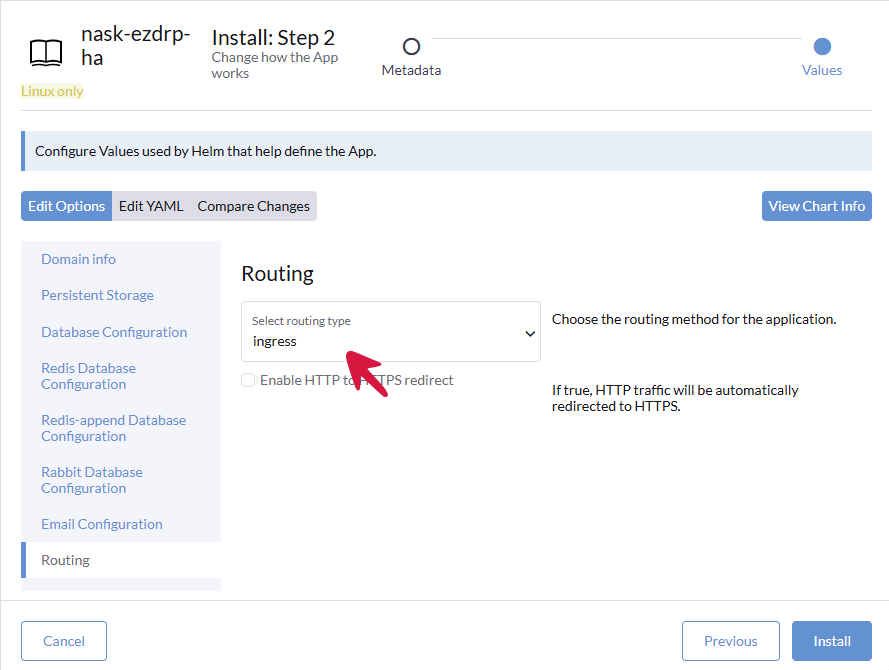
Następnie należy kliknąć zakładkę Edit YAML i zmienić wartości flag poniżej.
| Flaga | Wartość | Opis |
|---|---|---|
| Ezdrp_Feature_NoweZadania | Enabled | Uruchamianie nowych zadań na całej instancji. |
| Ezdrp_Feature_PrzydzielanieDostepow | Enabled | Przydzielanie dodatkowych dostępów do spraw w ramach klas JRWA. |
| Ezdrp_Feature_Wew | Enabled | Rejestr pism wewnętrznych. |
| Ezdrp_Feature_EpuapWysylkaPlikowStrumieniowo | Enabled | Wysyłka epuap strumieniowo. |
Po wprowadzeniu zmian klikamy przycisk Install. Po prawidłowej instalacji w logu powinien pojawić się napis SUCCESS.

7.8 Usuwanie zadań dla baz danych MS SQL (opcjonalnie)
Gdy wykorzystaliśmy bazę danych MS SQL, należy wykonać punkt 4 z instrukcji.
7.9 Zmniejszenie uprawnień dla NFS
Wracamy na serwer NFS w celu zmniejszenia uprawnień.
sudo nano /etc/exportsUsuwamy ze wszystkich linii parametr no_root_squash i zapisujemy.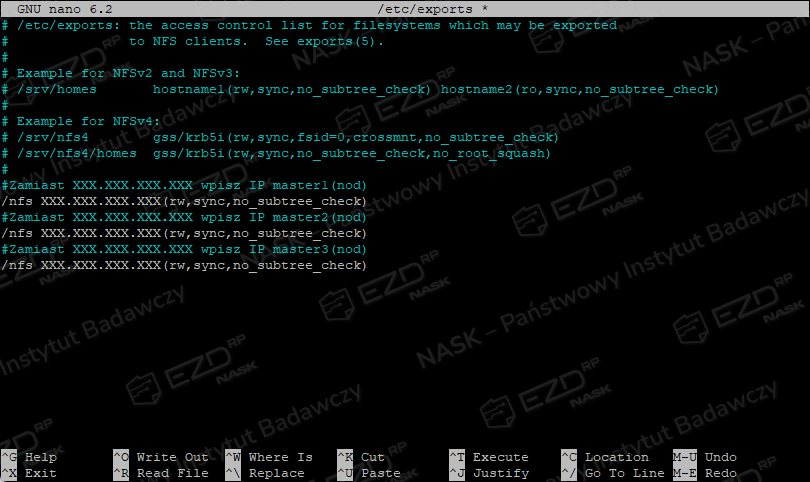
Następnie restartujemy serwer NFS.
sudo systemctl restart nfs-server7.10 Konfiguracja DNS
W zakładce Service Discovery > Ingresses będzie widoczna lista domen, jakie należy dodać do serwera DNS lub na komputerze w hosts. Wszystkie muszą wskazywać na adres IP serwera HAProxy. Jeżeli wykonany został punkt 3.7 instrukcji, należy wprowadzić adres IP VIP.
Przykład hostów dla domeny nask.pl z certyfikatem Wildcard:
x.x.x.x connectors.nask.pl
x.x.x.x ezdrp-web.nask.pl
x.x.x.x ezdrp-api.nask.pl
x.x.x.x ezdrp-forms.nask.pl
x.x.x.x filerepo-api.nask.pl
x.x.x.x integrator-api.nask.pl
x.x.x.x kuip-api.nask.pl
x.x.x.x kuip-web.nask.pl
x.x.x.x sso-extidp.nask.pl
x.x.x.x sso-idp.nask.pl
Wpisy DNS:
connectors
ezdrp-web
ezdrp-api
ezdrp-forms
filerepo-api
integrator-api
kuip-api
kuip-web
sso-extidp
sso-idp
Po dodaniu wszystkich wpisów DNS upewniamy się, czy adresy działają i kierują na serwer aplikacyjny.
7.11 Pobranie hasła do systemu EZD RP
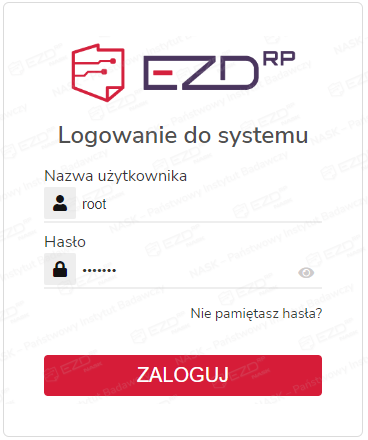
Podczas pierwszego uruchomienia kontenera kuip-api (na pustej bazie) tworzone jest konto admina root.
Logowanie do systemu odbywa się z użyciem nazwy użytkownika (root) oraz hasła.
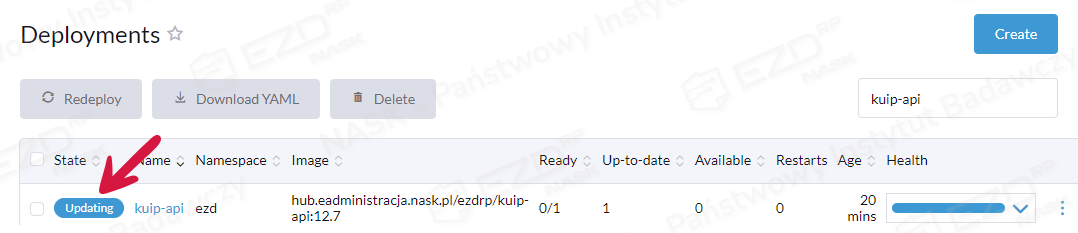
Chcąc zresetować hasło, należy wybrać w zakładce Workload pozycję Deployments. Wyszukujemy kuip-api i klikamy Edit Config.
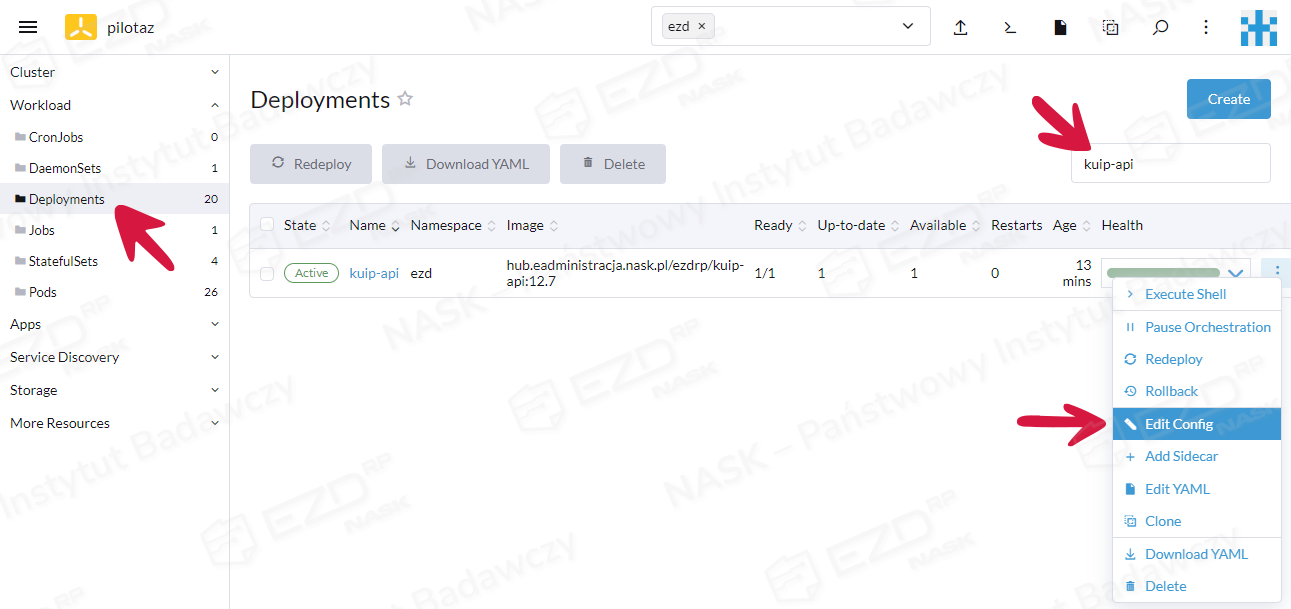
W sekcji General > Environment Variables klikamy przycisk Add Variable.
Z rozwijanej listy w polu Type wybieramy Key/Value Pair. Z kolei w polu Variable Name wpisujemy KUIP_ROOT_RESET_PASSWORD, a w polu Value podajemy nowe hasło.
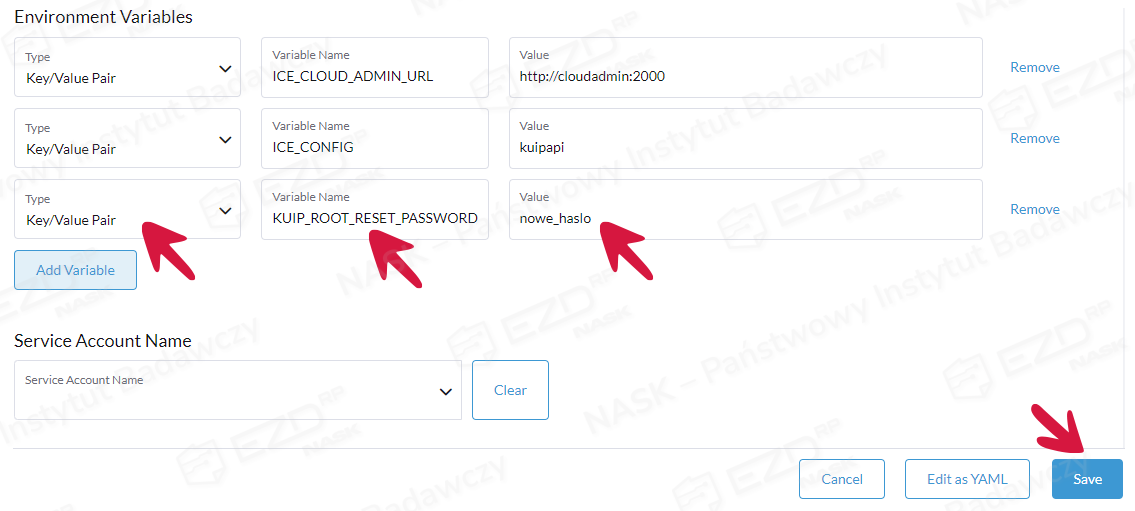
Zapisujemy ustawienia, klikając przycisk Save. Po chwili redeployment kuip-api powinien zostać zakończony automatycznie (zmiana statusu z Updating na Active).
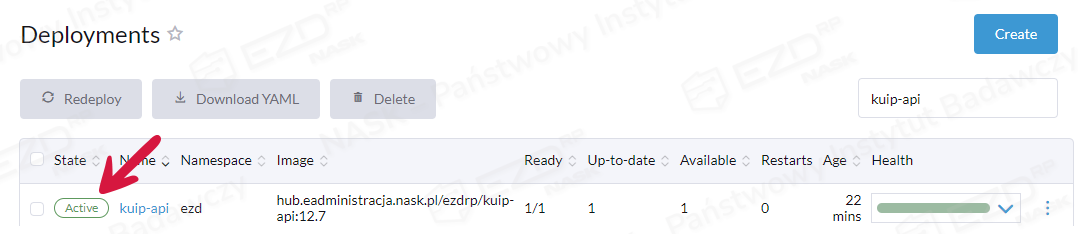
Po wykonaniu tej operacji możliwe jest zalogowanie się do aplikacji na konto użytkownika root za pomocą nowego hasła podanego w zmiennej środowiskowej KUIP_ROOT_RESET_PASSWORD.
Aby zalogować się do systemów EZD RP i KUiP, należy wpisać w przeglądarce dwa adresy zbudowane według następującego schematu:
- https://ezdrp-web.twoja_domena/
- https://kuip-web.twoja_domena/
W naszym przykładzie są to adresy:
- https://ezdrp-web.nask.pl/
- https://kuip-web.nask.pl/
Rekomendowane porty do odblokowania na firewallu
HAProxy:
80/TCP (HTTP), 443/TCP (HTTPS), 8404/TCP (Statystyki HAProxy), 9345/TCP (API RKE2)
HAProxy1:
odblokować połączenie z IP HAProxy2
HAProxy2:
odblokować połączenia z IP HAProxy1
Postgresql:
5432/TCP
MS SQL:
1433/TCP, 1434/UDP
Redis:
6379/TCP, 6380/TCP
Rabbit:
5672/TCP, 15672/TCP (WEB)
NFS:
2049/TCP
Mastery:
80/TCP (HTTP), 443/TCP (HTTPS), 2379,2380/TCP (ETCD), 6443/TCP (Kubectl), 8472/UDP (Flannel VXLAN), 9345/TCP (RKE2), 10250/TCP (Kubelet)
Rancher:
8443/TCP (HTTPS)